本地RAG增强检索实现
Spring-AI+Ollama+RedisStack实现本地RAG增强检索
Rag简述
市面上所有的LLM(大语言模型)都是没有记忆功能的;比如 ChatGpt,所谓的记忆功能只是当你发送消息给 ChatGpt时,程序会自动将最近的几次对话记录通过prompt组合成最终的问题,并发送给 ChatGpt。但是所有的LLM都有Tokens数量的限制,也就是说如果提问的问题字数超出一定数量他就会忘记之前的对话。
当我们需要AI根据知识库来回来问题时,就会面临以下问题:
- 我们每次提问都需要发送完整的知识库给AI让他阅读理解(AI没有记忆),AI阅读大量文本需要的时间非常长。
- 目前的ai都是按照tokens(字数)收费的,我们每次发送问题都是一大笔费用。
- 很多知识库都是内部的,我们并不想将他发送给公有的AI
RAG就是为了解决上述问题,的解决方案就
RAG流程:
- 将文档使用嵌入式模型向量化并存储。
- 当用户提问时,将用户问题向量化,并从之前存储的文档中查出相似的相关文档。
- 将相关的文档拼接起来与用户问题组合成提示词,向大预言模型提问。

向量数据库
SpringAI支持的向量数据库种类很多,本文采用RedisStack作为向量数据库。
不建议用
PGvector,因为他的向量类型只支持最大两千的切片,现在很多模型的嵌入切片都远远超过2000了,所以很多模型都无法使用他存储向量值。
Redis Stack是Redis的扩展,增加了现代数据模型和处理引擎,从而为开发者提供了完整的开发体验
RedisStack部署:
redisStack分为redisStackServer和redisStack;redisStackServer不包含客户端,可以按需选择。
Docker地址:
redisStack部署命令
docker run -d --name redis-stack \
--restart=always \
-p 6379:6379 -p 8001:8001 \
-e REDIS_ARGS="--requirepass 123456" \
-v /data/redis-stack/data:/data \
redis/redis-stack:latest
- 镜像:
redis/redis-stack - 端口:
6379端口是redis-stack-server的服务端口,8001是redis-stack-client的端口 - 初始密码设置:
-e REDIS_ARGS="--requirepass 123456" - 将数据挂载到宿主机:
-v /data/redis-stack/data:/data
确保服务器中有
/data/redis-stack/data目录,或者使用容器卷。
本地部署大模型
很多组织都开源了自己做好的大模型,我们可以将这些大模型部署到本地使用。
本地部署大模型的方法有:
- VLLM
- Llama.cpp
- Hugging Face
- Ollama
我们使用Ollama来部署大模型,他的优势:
- Ollama的下载安装以及运行模型极其简单。
- Ollama提供了类似OPENAI风格一致的API.
- Ollama本身有模型仓库,里面有市面上大部分的模型。
- SpringAI已经集成了Ollama,可以做到开箱即用。
Ollama安装
参考: https://www.53ai.com/news/LargeLanguageModel/2024081317230.html
MacOs、Windows下载安装
macOS:https://ollama.com/download/Ollama-darwin.zip
Windows:https://ollama.com/download/OllamaSetup.exe
Ollama命令
命令和Docker很类似
ollama serve # 启动ollama
ollama create # 从模型文件创建模型
ollama show # 显示模型信息
ollama run # 运行模型,会先自动下载模型
ollama pull # 从注册仓库中拉取模型
ollama push # 将模型推送到注册仓库
ollama list # 列出已下载模型
ollama ps # 列出正在运行的模型
ollama cp # 复制模型
ollama rm # 删除模型
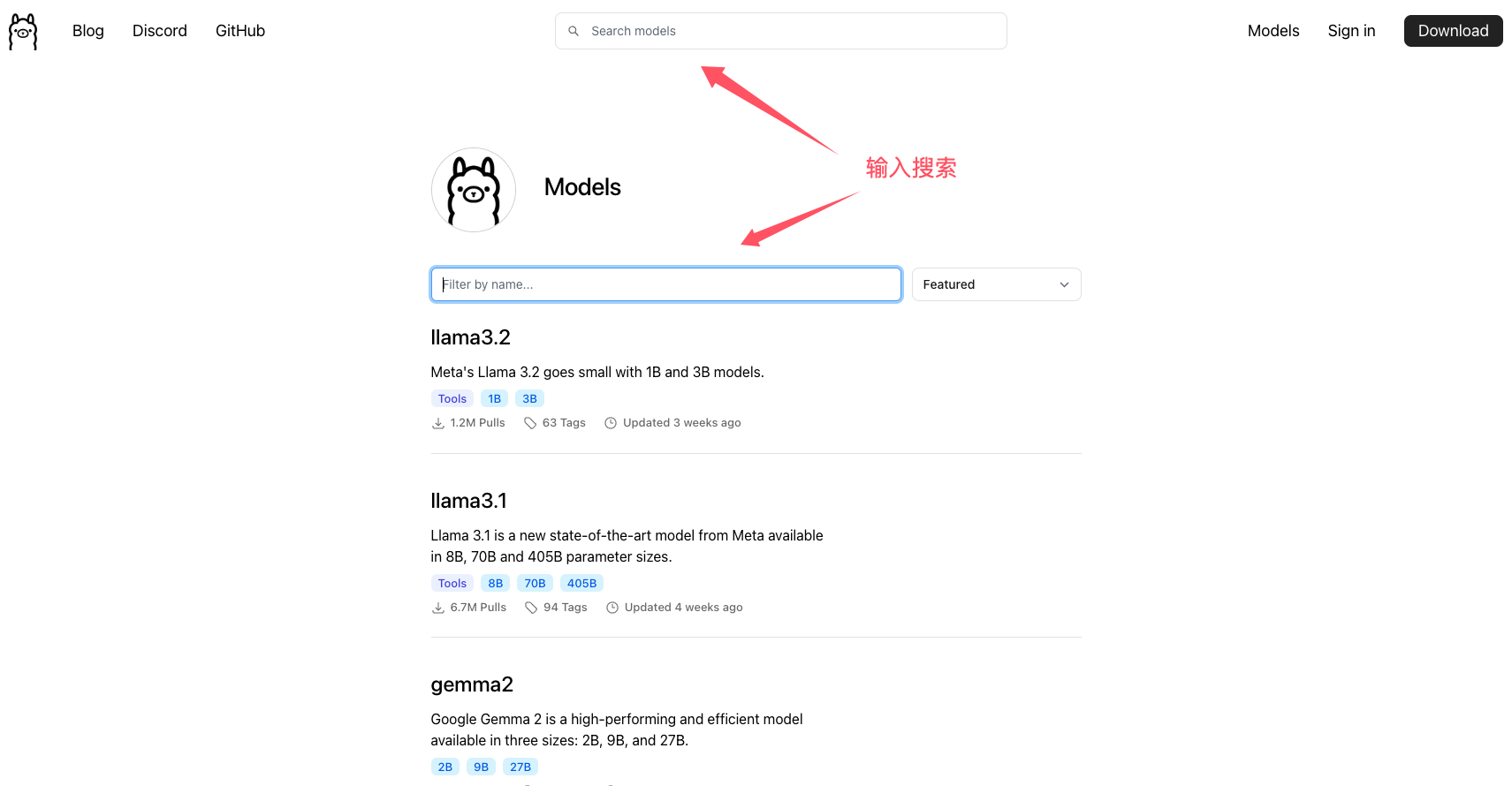
Ollama模型库
与docker一样,Ollama也有一个模型库。我们可以浏览模型库查找我们需要的模型。
运行GML4-9B
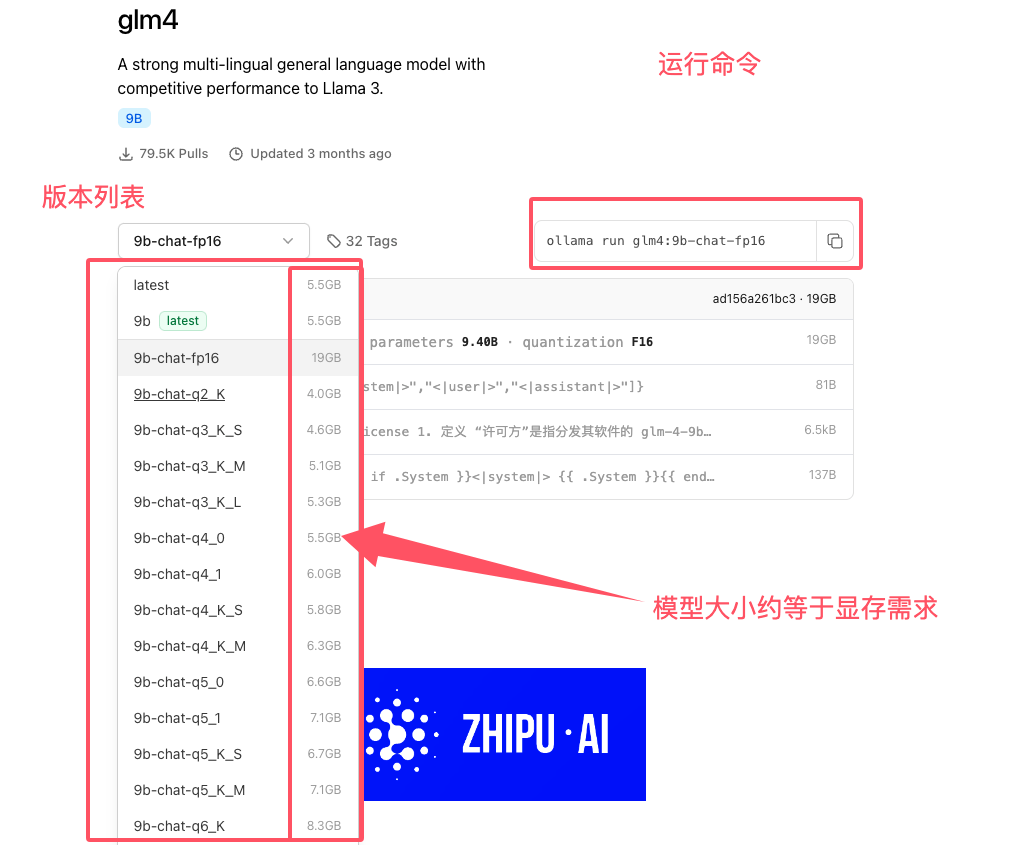
运行命令:ollama run glm4:9b-chat-fp16 (我本地用的4_1)

测试一下:
/root # curl --request POST \
--url http://localhost:11434/api/chat \
--header 'Content-Type: application/x-www-form-urlencoded' \
--header 'content-type: application/json' \
--data '{
"model": "glm4:9b-chat-q4_1",
"stream": false,
"messages": [
{
"role": "user",
"content": "你好, 你是谁"
}
]
}'
{
"model": "glm4:9b-chat-q4_1",
"created_at": "2024-10-18T12:01:04.607316Z",
"message": {
"role": "assistant",
"content": "你好,我是一个人工智能助手,专门设计来帮助回答问题和提供信息的。我的目的是在遵守社会主义价值观的前提下,为您提供服务。请问有什么可以帮助您的吗?"
},
"done_reason": "stop",
"done": true,
"total_duration": 10733145000,
"load_duration": 9122525667,
"prompt_eval_count": 10,
"prompt_eval_duration": 306385000,
"eval_count": 33,
"eval_duration": 1303184000
}
正常返回代表模型已经运行成功了
SpringAI
SpringAI项目旨在简化包含人工智能功能的应用程序的开发,同时避免不必要的复杂性。
- 支持多种AI模型:Chat(聊天)、Embeddings(嵌入)、Image(图像)、Audio(音频)、Moderation(审核)
- 支持多种向量数据库:Qdrant、Oracle、Neo4j、MongoDB、ElasticSearch、Redis、PGvector等
- 同时还支持高级Prompts以及ETL管线等与AI应用相关的功能。
环境要求
- java17+
- SpringBoot3.2+
springAI集成
- 添加spring的快照和里程碑存储库。
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
- 增加spring-ai的pom
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-SNAPSHOT</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
引入RAG需要的包
<dependencies>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
</dependency>
<!-- spring-ai-ollama -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
<!-- spring-ai-redis-store -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-redis-store</artifactId>
</dependency>
<!-- spring-ai-document-reader -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<!-- jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
</dependencies>
配置文件:
server:
port: 8080
spring:
data:
redis:
database: 0
timeout: 10s
lettuce:
pool:
# 连接池最大连接数
max-active: 200
# 连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: -1ms
# 连接池中的最大空闲连接
max-idle: 10
# 连接池中的最小空闲连接
min-idle: 0
repositories:
enabled: false
password: 123456
port: 16379
servlet:
multipart:
enabled: true #是否启用http上传处理
max-file-size: 100MB #设置单个文件最大长度
max-request-size: 100MB #最大请求文件的大小
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: glm4:9b-chat-q4_1
embedding:
options:
model: glm4:9b-chat-q4_1
vectorstore:
redis:
initialize-schema: true
新增SpringAi配置
需要注意:一定要禁用springAi的redis配置
/**
* @Description: springai
* @Author: chenrui
* @Date: 2024/10/16 10:43
*/
@Configuration
// 禁用SpringAI提供的RedisStack向量数据库的自动配置,会和Redis的配置冲突。
@EnableAutoConfiguration(exclude = {RedisVectorStoreAutoConfiguration.class})
// 读取RedisStack的配置信息
@EnableConfigurationProperties({RedisVectorStoreProperties.class})
@AllArgsConstructor
public class AiConfiguration {
/**
* 文档分割
* @return
* @author chenrui
* @date 2024/10/18 20:07
*/
@Bean
public DocumentTransformer documentTransformer() {
return new TokenTextSplitter();
}
/**
* 创建RedisStack向量数据库
* 因为springAI的RedisStack不能设置密码,所以我们要自定义RedisStack的连接
* @param embeddingModel 嵌入模型
* @param properties redis-stack的配置信息
* @return vectorStore 向量数据库
*/
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel,
RedisVectorStoreProperties properties,
RedisConnectionDetails redisConnectionDetails) {
RedisVectorStore.RedisVectorStoreConfig config = RedisVectorStore.RedisVectorStoreConfig.builder().withIndexName(properties.getIndex()).withPrefix(properties.getPrefix()).build();
return new RedisVectorStore(config, embeddingModel,
new JedisPooled(redisConnectionDetails.getStandalone().getHost(),
redisConnectionDetails.getStandalone().getPort()
, redisConnectionDetails.getUsername(),
redisConnectionDetails.getPassword()),
properties.isInitializeSchema());
}
}
resources中新增提示词模板文件

rag.st
以下是上下文信息:
---------------------
{context}
---------------------
根据上下文信息而非已有知识回答问题。
如果上下文信息无法提供有效答案,请尝试使用您自己的数据库进行回复,并且告诉用户该信息不是来自上下文信息。
如果您的数据库仍无法回答该问题,请回复“不知道”。
请用简体中文作答。
问题:{question}
答案:
新增Controller
package org.jeecg.ai.ollama.controller;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.SystemPromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentTransformer;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.util.List;
import java.util.Map;
@RestController
@RequestMapping("/ai")
public class AiController {
@Value("classpath:rag.st")
private Resource promptResource;
private final VectorStore vectorStore;
private final DocumentTransformer documentTransformer;
private final OllamaChatModel ollamaChatModel;
public AiController(VectorStore vectorStore, DocumentTransformer documentTransformer, OllamaChatModel ollamaChatModel) {
this.vectorStore = vectorStore;
this.documentTransformer = documentTransformer;
this.ollamaChatModel = ollamaChatModel;
}
/**
* 上传文档到向量库
* @param file
* @return
* @author chenrui
* @date 2024/10/18 20:13
*/
@PostMapping("file/upload")
public Object uploadFile(MultipartFile file){
try {
Resource resource = file.getResource();
TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(resource);
List<Document> fileDocuments = tikaDocumentReader.get();
List<Document> documents = documentTransformer.apply(fileDocuments);
vectorStore.accept(documents);
return "上传成功";
}catch (Exception e){
return e.getCause();
}
}
@GetMapping("chat/rag")
public String ragChat(String prompt){
// 从向量数据库中搜索相似文档
List<Document> documents = vectorStore.similaritySearch(prompt);
// 获取documents里的content
List<String> context = documents.stream().map(Document::getContent).toList();
// 创建系统提示词
SystemPromptTemplate promptTemplate = new SystemPromptTemplate(promptResource);
// 填充数据
Prompt p = promptTemplate.create(Map.of("context", context, "question", prompt));
ChatResponse response = ollamaChatModel.call(p);
AssistantMessage aiMessage = response.getResult().getOutput();
return aiMessage.getContent();
}
}
启动测试
项目启动后
首先通过ai/file/upload接口上传帮助文档。
curl --request POST \
--url http://localhost:8080/ai/file/upload \
--header 'content-type: multipart/form-data' \
--form 'file=@/Users/chenrui/work/temp/素材/JeecgBoot开发文档-05131420-节选100页.pdf'
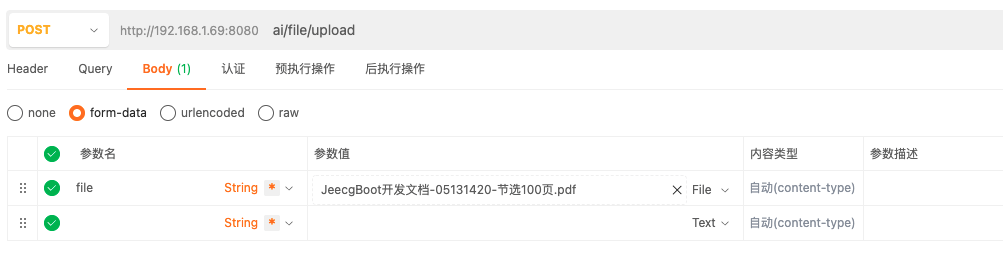 上传成功后可以在redis中看到
上传成功后可以在redis中看到
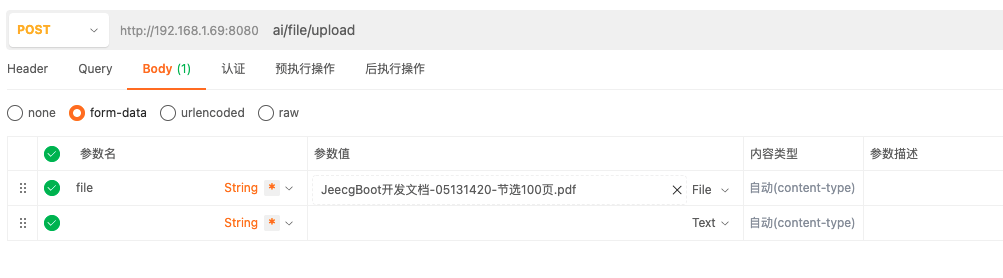
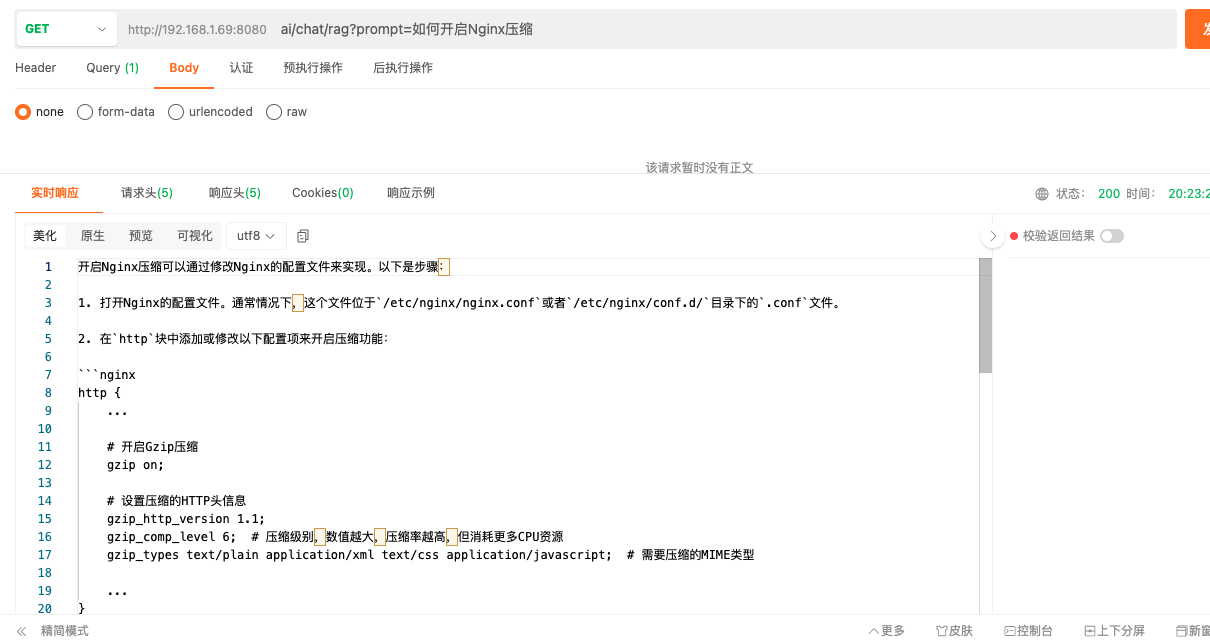
文档上传成功后,可以通过ai/chat/rag接口发送rag问题。
curl --request GET \
--url 'http://localhost:8080/ai/chat/rag?prompt=如何开启Nginx压缩'
待解决问题
文档里的图片怎么存储和搜索
坑
springAI现在还没有出正式版,每个版本之间差异很大