SQL优化技巧
sql优化技巧
慢查询
慢查询(Slow Query)指的是执行时间较长,性能较差的SQL查询语句,通常在数据库系统中会显著影响整体性能。慢查询可能导致响应时间增加,阻塞其他操作,从而影响用户体验或后台处理的效率。
mysql中获取慢查询语句
mysql开启慢查询
临时开启
-- 切换数据库
use jeecgboot;
-- 设置开启慢查询日志
SET GLOBAL slow_query_log = 1;
-- 设置慢查询阈值
SET GLOBAL long_query_time=1;
-- 查看慢查询是否开启
SHOW VARIABLES LIKE '%slow_query_log%';
-- 查看慢查询阈值
show global variables like 'long_query_time';
永久开启(不建议)
# my.cnf
[mysqld]
# 开启慢查询
slow_query_log=ON
# 指定存储慢查询日志的文件。如果这个文件不存在,会自动创建
slow_query_log_file=/var/lib/mysql/slow.log
# 设置慢查询阈值(单位:s)
long_query_time=1
查看慢查询语句
cat /var/lib/mysql/c65f6d071766-slow.log
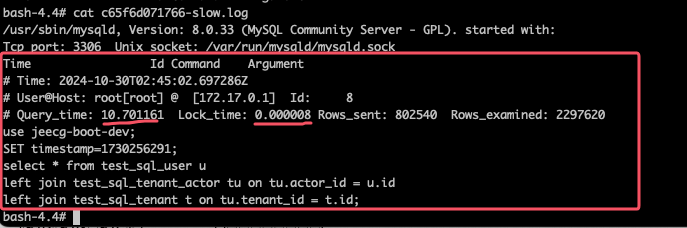
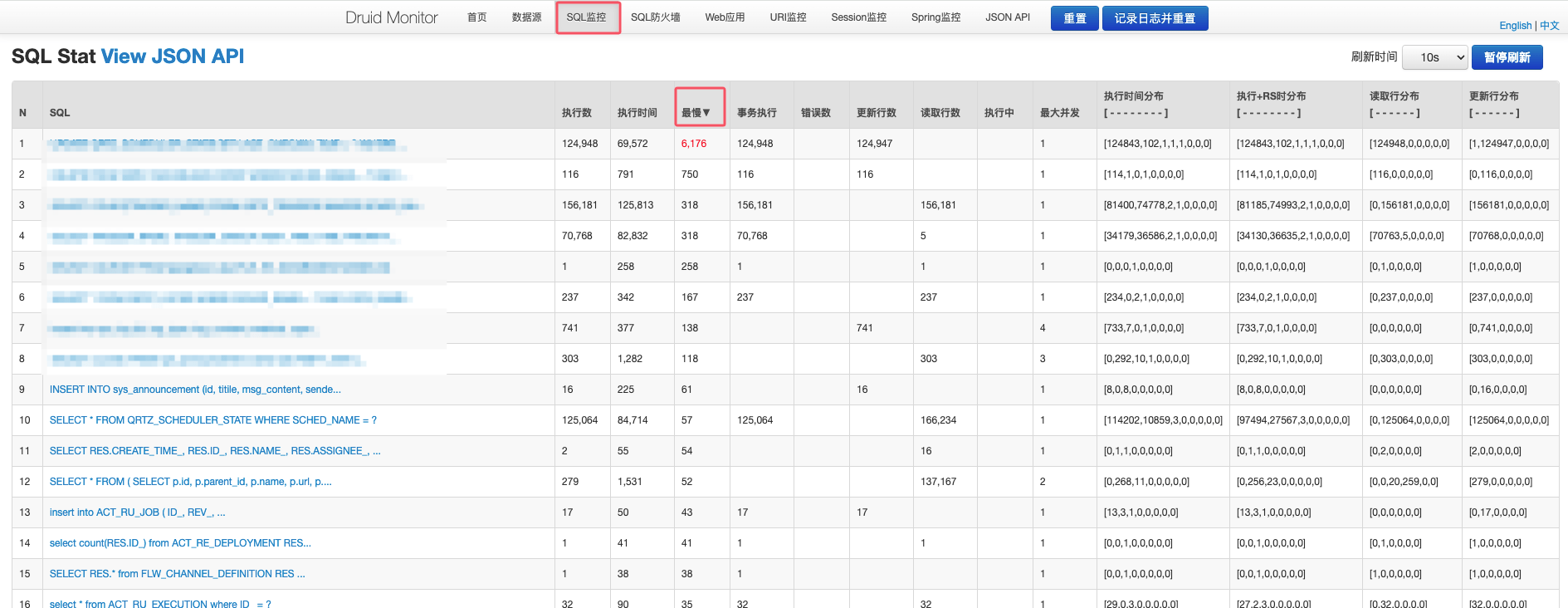
使用druid获取慢查询语句
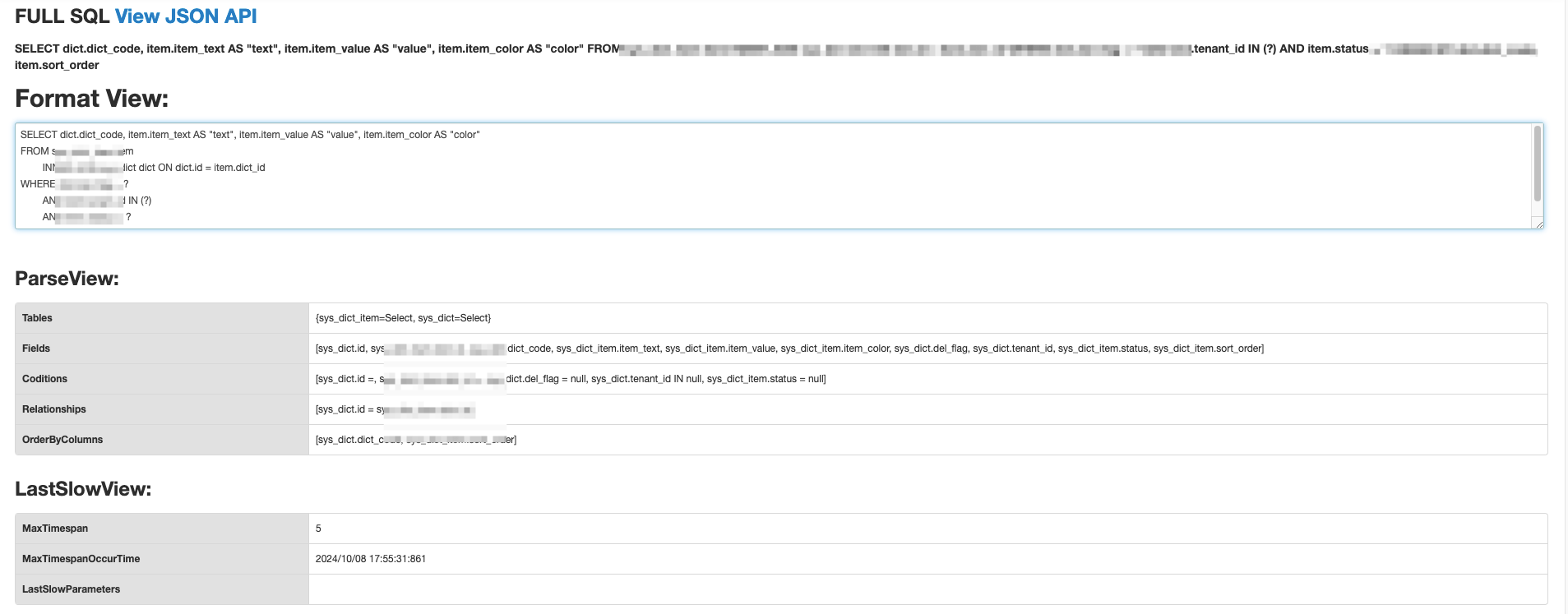
sql优化
sql查询流程

解析器
优化器
mysql 中有专门负责优化 select 语句的优化器模块,主要功能:通过计算分析系统中收集到的统计信息,为客户端请求的 query 提供他认为最优的执行计划 (他认为最优的数据检索方式但不见得是 DBA 认为最优的,所以这部分最浪费时间)
基于查询流程的优化
尽量不要用*
- 分析成本高
- 获取数据开销大
- 内存占用大
- 无法利用覆盖索引
SQL务必要写完整,不要使用缩写法
select name "姓名" from user;
select * from t1,t2 where t1.f = t2.f;
所有缩写的写法,在MySQL底层都需要做一次转换,将其转换为完整的写法,因此简写的SQL会比完整的SQL多一步转化过程,如果你考虑极致程度的优化,也切记将SQL写成完整的语法。
select name as "name" from user;
select * from t1 t1 inner join t2 t2 on t1.f段 = t2.f;
明确仅返回一条数据的语句可以使用limit x
select * from t where name = 'c';
select * from t where name = 'c' limit 1;
上述这两条SQL语句都是根据姓名查询一条数据,但后者大多数情况下会比前者好,因为加上limit 1关键字后,当程序匹配到一条数据时就会停止扫描,如果不加的情况下会将所有数据都扫描一次。所以一般情况下,如果确定了只需要查询一条数据,就可以加上limit 1提升性能。
小表驱动大表
select * from test_sql_user u
left join test_sql_tenant_actor tu on tu.actor_id = u.id
left join test_sql_tenant t on tu.tenant_id = t.id
limit 1000;

select SQL_NO_CACHE * from test_sql_tenant t
left join test_sql_tenant_actor tu on tu.tenant_id = t.id
left join test_sql_user u on tu.actor_id = u.id
limit 1000;

连表查询时尽量不要关联太多表
- 数据量会随表数量呈直线性增长,数据量越大检索效率越低。
- 当关联的表数量过多时,无法控制好索引的匹配,涉及的表越多,索引不可控风险越大。
尽量避免深分页的情况出现
select xx,xx,xx from yyy limit 100000,10;
上述这条SQL相当于查询第1W页数据,在MySQL的实际执行过程中,首先会查询出100010条数据,然后丢弃掉前面的10W条数据,将最后的10条数据返回,这个过程无异极其浪费资源。
select xx,xx,xx from yyy where sort >= n limit 10;
索引
什么是索引
假设数据是下图这样存储的。
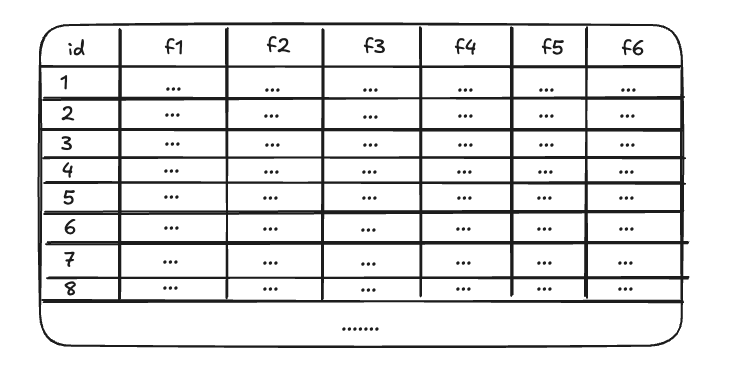
需要查询id=8的值时,需要遍历所有数据,直到找到所有id=8的数据。
索引是对数据库表中一列或多列的值进行排序的一种数据结构,使用索引可以快速访问数据库表中的特定信息。
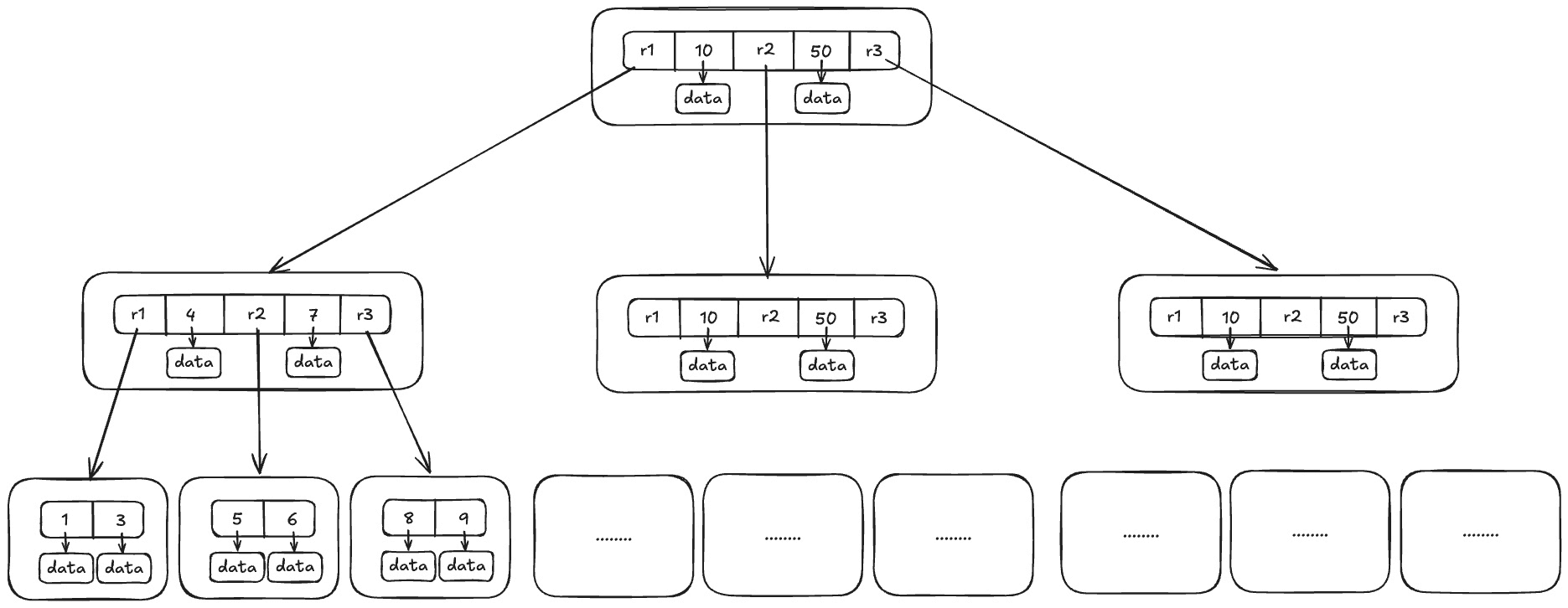
InnoDB 存储引擎:B+ 树索引的叶子节点保存数据本身,其数据文件本身就是索引文件。
二级索引
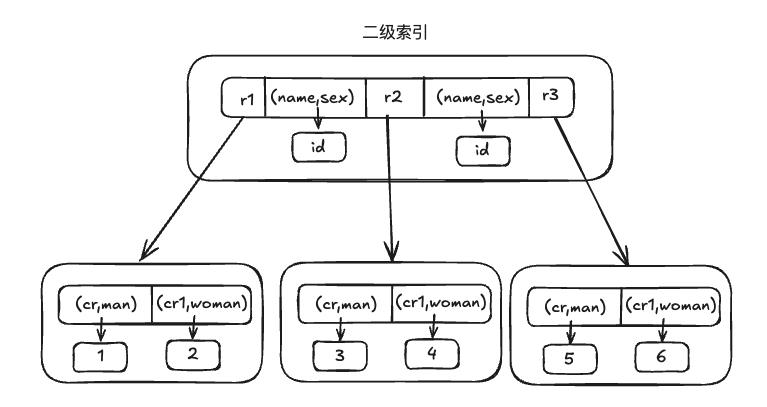
索引类型:
- 唯一索引:唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。
- 普通索引:普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
- 前缀索引:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
- 全文索引:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。
索引方法:
B-Tree:多路平衡查找树 ,B+ 树是 B 树的一种变体。B 树和 B+树中的 B 是 Balanced (平衡)的意思。HASH:哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
索引失效
- 对索引使用左或者左右模糊匹配,也就是
like %xx或者like %xx%这两种方式都会造成索引失效。原因在于查询的结果可能是多个,不知道从哪个索引值开始比较,于是就只能通过全表扫描的方式来查询。 - 对索引进行函数/对索引进行表达式计算,因为索引保持的是索引字段的原始值,而不是经过函数计算的值,自然就没办法走索引。
- 对索引进行隐式转换相当于使用了新函数。
- WHERE 子句中的 OR语句,只要有条件列不是索引列,就会进行全表扫描。
- 如果字段类型是字符串,where时一定用引号括起来,否则索引失效
- 联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
- 对索引列运算(如
,+、-、*、/),索引失效。 - 索引字段上使用(
!= 或者 < >,not in)时,可能会导致索引失效。 - 索引字段上使用
is null, is not null,可能导致索引失效。 - 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
- mysql 估计使用全表扫描要比使用索引快,则不使用索引。
explain
用法:EXPLAIN <SQL>
mysql> explain select * from test_sql_user u;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
| 1 | SIMPLE | u | NULL | ALL | NULL | NULL | NULL | NULL | 644930 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
1 row in set, 1 warning (0.01 sec)
id
这是执行计划的ID值,一条SQL语句可能会出现多步执行计划,所以会出现多个ID值,这个值越大,表示执行的优先级越高:
- 值相同,由上向下执行;
select * from test_sql_user u
left join test_sql_tenant_actor tu on tu.actor_id = u.id
left join test_sql_tenant t on tu.tenant_id = t.id
limit 1000;
- ID值不同,值越大优先级越高
select * from test_sql_user u where u.id in (select actor_id from test_sql_tenant_actor ta where ta.is_main = 'Y' and ta.actor_id like '012ec46995e011e%')
limit 1000;
- ID值为空,ID=null时,会放在最后执行。
select_type
当前执行的select语句其具体的查询类型:
SIMPLE:简单的select查询语句,不包含union、子查询语句。PRIMARY:union或子查询语句中,最外层的主select语句。SUBQUEPY:包含在主select语句中的第一个子查询,如select ... xx = (select ...)。DERIVED:派生表,指包含在from中的子查询语句,如select ... from (select ...)。UNION:多条语句通过union组成的查询中,第二个以及更后面的select语句。UNION RESULT:union的结果集。
这个字段主要是说明当前查询语句所属的类型,以及在整条大的查询语句中,当前这个查询语句所属的位置。
table
当前执行的select的哪一张表,可能是物理表,也有可能是子查询的结果

type
all:全表扫描,基于表中所有的数据,逐行扫描并过滤符合条件的数据。index:全索引扫描,和全表扫描类似,但这个是把索引树遍历一次,会比全表扫描要快。range:基于索引字段进行范围查询,如between、<、>、in....等操作时出现的情况。fulltext:基于全文索引字段,进行查询时出现的情况。ref:基于非主键或唯一索引字段查找数据时,会出现的情况。eq_ref:连表查询时,基于主键、唯一索引字段匹配数据的情况,会出现多次索引查找。const:通过索引一趟查找后就能获取到数据,基于唯一、主键索引字段查询数据时的情况。system:表中只有一行数据,这是const的一种特例。null:表中没有数据,无需经过任何数据检索,直接返回结果。
性能排序:system > const > eq_ref > ref > fulltext > range > index > all
possible_keys 和 key
possible_keys: 表示 sql 内部分析出来的该条 sql 应该会被用到的索引
key: 表示实际的 sql 执行过程当中被用到的索引是哪一个 我们可以通过判断 key 的值是否是 null 来判断索引是否失效没有被用上
主要有两种情况需要注意:
possible_keys有值,key也有值。代表我们创建的索引被正常使用了。possible_keys有值,key没有值。代表我们创建的索引但是索引没有用,这就是索引失效了。
ref
显示索引查找过程中,查询时会用到的常量或字段:
- const:如果显示这个,则代表目前是在基于主键字段值或数据库已有的常量(如null)查询数据。
- 显示具体的字段名:表示目前会基于该字段查询数据。

rows
执行时,预计会扫描的行数,这个数字对于InnoDB表来说,其实有时并不够准确,但也具备很大的参考价值,如果这个值很大,在执行查询语句时,其效率必然很低,所以该值越小越好。
extra
该字段会包含MySQL执行查询语句时的一些其他信息,这个信息对索引调优而言比较重要,可以带来不小的参考价值,但这个字段会出现的值有很多种,如下:
Using index:表示目前的查询语句,使用了索引覆盖机制拿到了数据。Using where:表示目前的查询语句无法从索引中获取数据,需要进一步做回表去拿表数据。Using temporary:表示MySQL在执行查询时,会创建一张临时表来处理数据。Using filesort:表示会以磁盘+内存完成排序工作,而完全加载数据到内存来完成排序。Select tables optimized away:表示查询过程中,对于索引字段使用了聚合函数。Using where;Using index:表示要返回的数据在索引中包含,但并不是索引的前导列,需要做回表获取数据。NULL:表示查询的数据未被索引覆盖,但where条件中用到了主键,可以直接读取表数据。Using index condition:和Using where类似,要返回的列未完全被索引覆盖,需要回表。Using join buffer (Block Nested Loop):连接查询时驱动表不能有效的通过索引加快访问速度时,会使用join-buffer来加快访问速度,在内存中完成Loop匹配。Impossible WHERE:where后的条件永远不可能成立时提示的信息,如where 1!=1。Impossible WHERE noticed after reading const tables:基于唯一索引查询不存在的值时出现的提示。const row not found:表中不存在数据时会返回的提示。distinct:去重查询时,找到某个值的第一个值时,会将查找该值的工作从去重操作中移除。Start temporary, End temporary:表示临时表用于DuplicateWeedout半连接策略,也就是用来进行semi-join去重。Using MRR:表示执行查询时,使用了MRR机制读取数据。Using index for skip scan:表示执行查询语句时,使用了索引跳跃扫描机制读取数据。Using index for group-by:表示执行分组或去重工作时,可以基于某个索引处理。FirstMatch:表示对子查询语句进行Semi-join优化策略。No tables used:查询语句中不存在from子句时提示的信息,如desc table_name;。
索引左前原则
select u.* from test_sql_user u
left join test_sql_tenant_actor tu on tu.actor_id = u.id
left join test_sql_tenant t on tu.tenant_id = t.id
where u.phone like '13896622%' and u.area > 7 and u.continuous_visit_days < 10 ;


索引的最左前缀原则,可以是联合索引的最左N个字段。比如你建立一个组合索引(a,b,c),其实可以相当于建了(a),(a,b),(a,b,c)三个索引,大大提高了索引复用能力。
当然,最左前缀也可以是字符串索引的最左M个字符。。比如,你的普通索引树是这样:

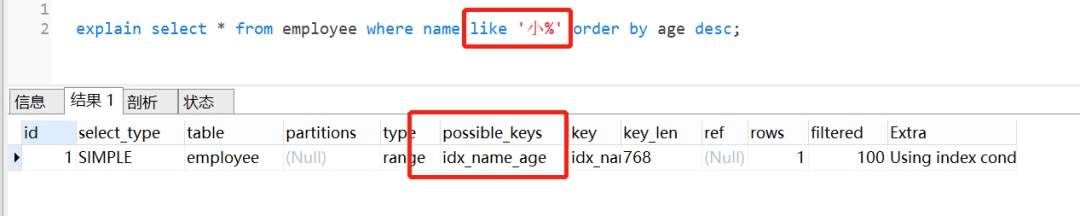
这个SQL: select * from employee where name like '小%' order by age desc; 也是命中索引的。
为什么有时候有索引,却不走索引?
比如 sex > 0 明明有索引,为什么不走?
select u.* from test_sql_user u
left join test_sql_tenant_actor tu on tu.actor_id = u.id
left join test_sql_tenant t on tu.tenant_id = t.id
where sex > 0 and u.area > 7 and u.continuous_visit_days < 10 ;
当优化器发现,走了索引但是优化效果不明显时,就不会走索引了。
回表操作、覆盖索引
select u.sex,u.area,u.continuous_visit_days from test_sql_user u
left join test_sql_tenant_actor tu on tu.actor_id = u.id
left join test_sql_tenant t on tu.tenant_id = t.id
where sex > 0 and u.area > 7 and u.continuous_visit_days < 10 ;
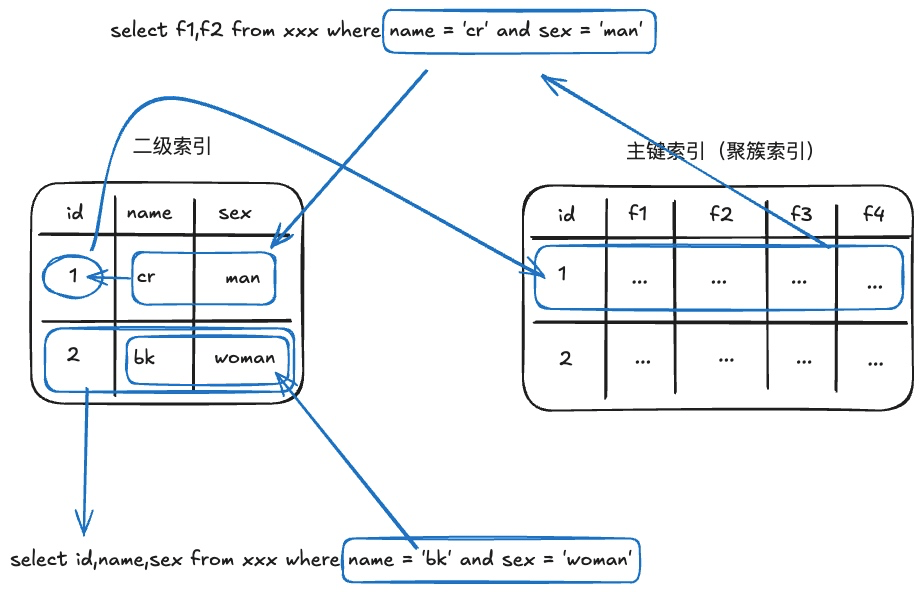
覆盖索引(covering index ,或称为索引覆盖)即从非主键索引中就能查到的记录,而不需要查询主键索引中的记录,避免了回表的产生减少了树的搜索次数,显著提升性能。 如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫 做覆盖索引
背景:索引分为主键索引(聚簇索引)和非主键索引(二级索引),主键索引中存储了整行数据,二级索引存储主键数据。 命中二级索引时,从二级索引中拿到数据主键,在用数据主键去主键索引中获取查询的数据。
- 覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
字符串加索引
- 直接创建完整索引,这样可能会比较占用空间。
- 创建前缀索引,节省空间,但会增加查询扫描次数,并且不能使用覆盖索引。
- 倒序存储,再创建前缀索引,用于绕过字符串本身前缀的区分度不够的问题。
- 创建 hash 字段索引,查询性能稳定,有额外的存储和计算消耗,跟第三种方式一样,都不支持范围扫描。
大表如何添加索引
如果一张表数据量级是千万级别以上的,那么,如何给这张表添加索引?
我们需要知道一点,给表添加索引的时候,是会对表加锁的。如果不谨慎操作,有可能出现生产事故的。可以参考以下方法:
- 先创建一张跟原表A数据结构相同的新表B。
- 在新表B添加需要加上的新索引。
- 把原表A数据导到新表B
- rename新表B为原表的表名A,原表A换别的表名;
附录
参考资料
https://juejin.cn/post/7164652941159170078
Mysql常见的优化手段和Explain关键字 Mysql深度讲解 – explain关键字 https://blog.csdn.net/weixin_43431218/article/details/129429287