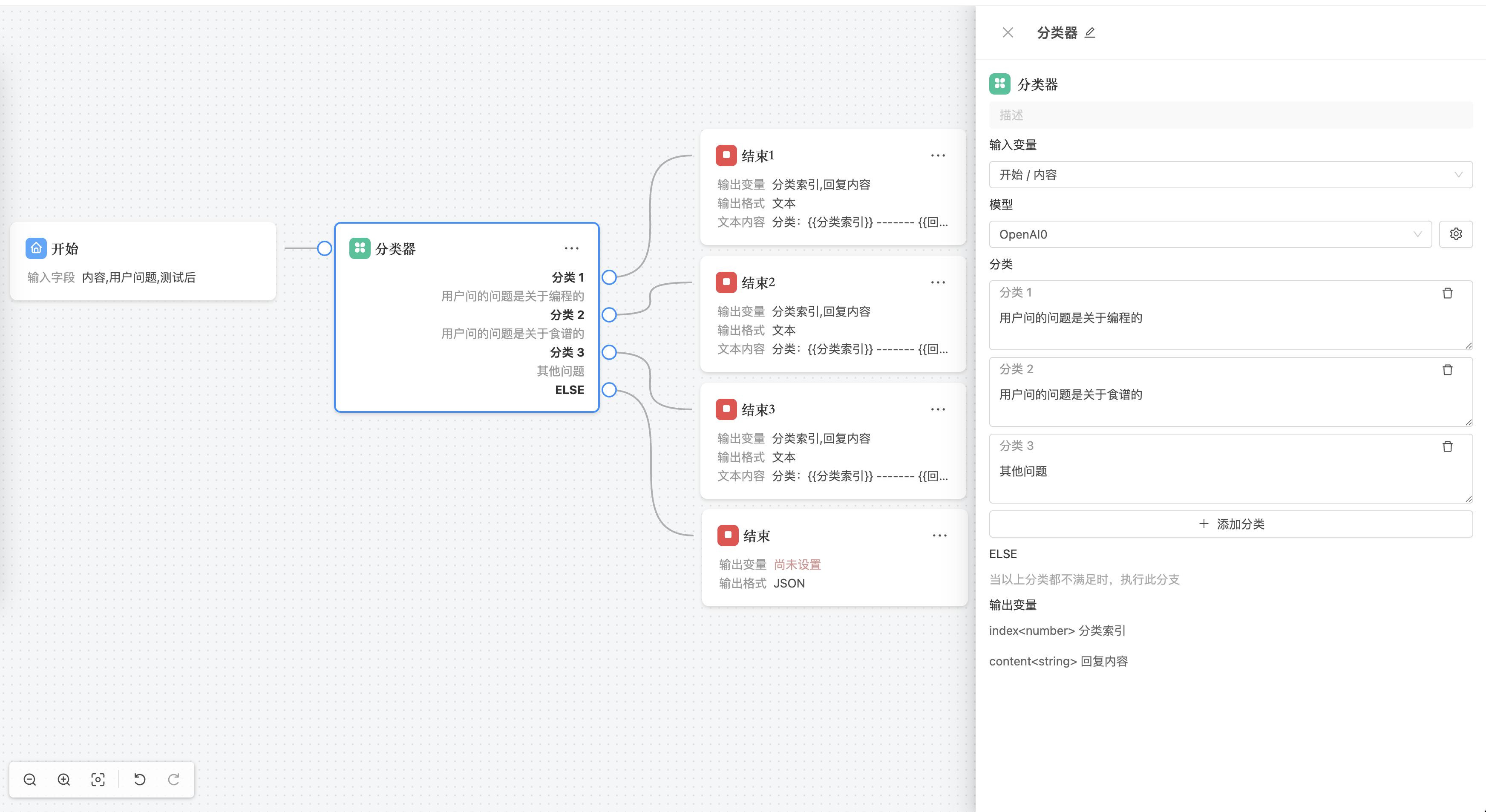
分类器节点
分类器节点可以让 AI 模型根据输入的内容,自动判断其类型或意图,并将内容流转到对应的工作流分支中。这使得智能系统能够实现更高效、更智能的流程自动化。
一、应用场景
分类器节点是 AI 模型最典型、最核心的能力之一。它不仅能理解用户使用自然语言表达的意图,还可以对其他节点输出的文本内容进行语义分析与分类。
例如,当用户输入「我想看一部文艺片」时,分类器节点可以识别出用户的意图为“电影推荐”,并将其自动引导至电影推荐的工作流分支中。
分类器节点具有极其广泛的应用价值,以下是常见的几个典型场景:
- 意图识别与流程分流: 判断用户输入的意图,并引导其进入相应的处理流程。
- 文本内容自动归类: 对新闻、评论、邮件等文本信息进行主题分类。
- 多语言指令识别与处理: 能够理解多种语言表达的指令,并正确归类与执行。
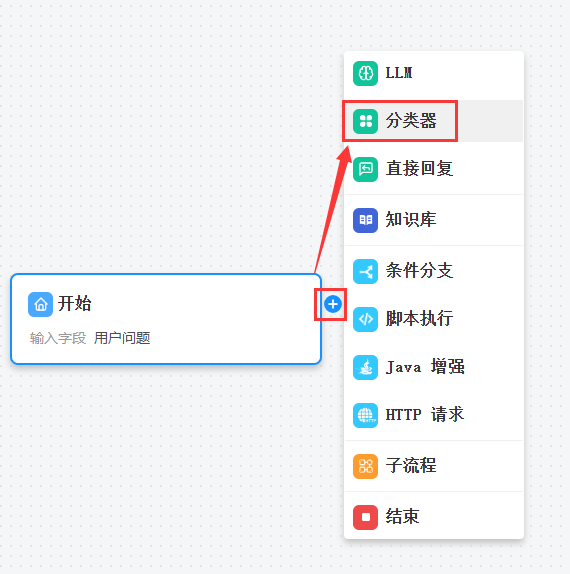
二、添加分类器节点
点击前一节点的![]() ,选中分类器节点,添加即可
,选中分类器节点,添加即可
三、节点配置详解
选中添加的分类器节点,即可详细配置此节点
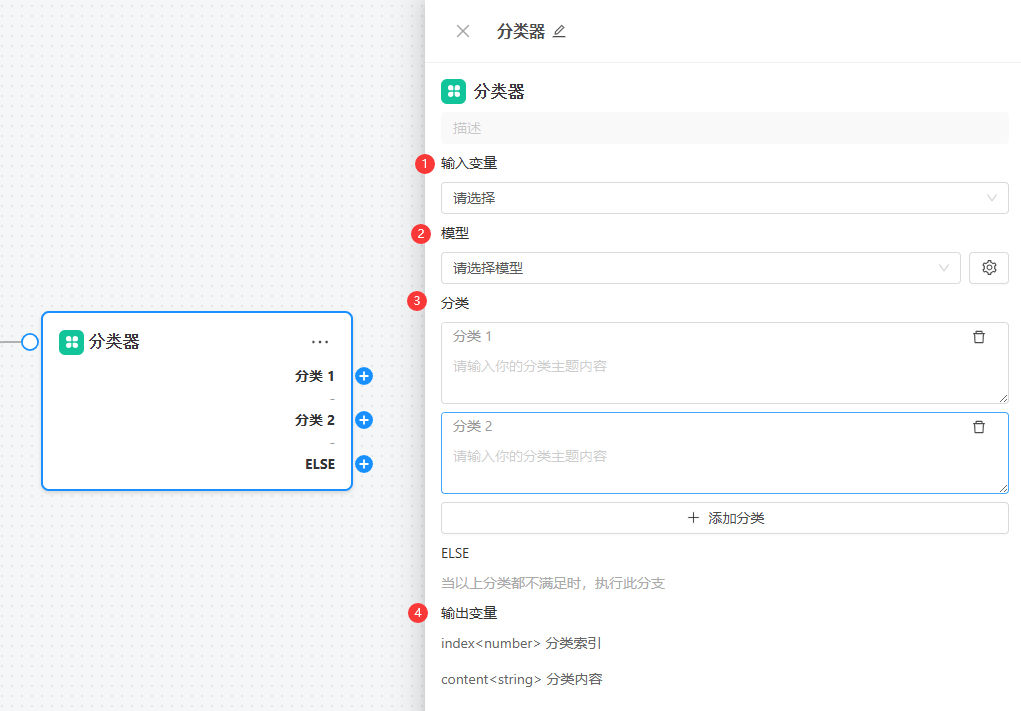
1. 输入变量
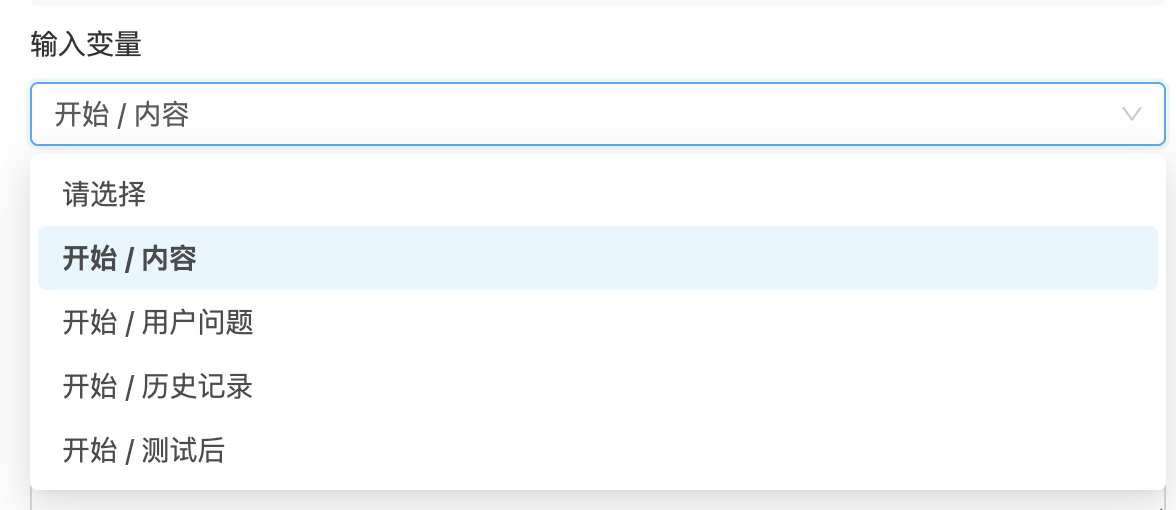
输入变量用于定义传递给分类器节点的参数来源。分类器将基于该输入变量的内容进行语义分析,并判断其类型或意图。
在节点的右侧配置面板中,可以通过下拉框选择变量的来源。变量必须来自当前节点之前的节点(通过连线连接),不能引用后续或并行节点的数据。
2. 模型选择与配置
分类器节点支持灵活选择并配置使用的模型,输出效果与模型的选择密切相关。所有模型均可在 AI 模型配置 模块中统一管理。
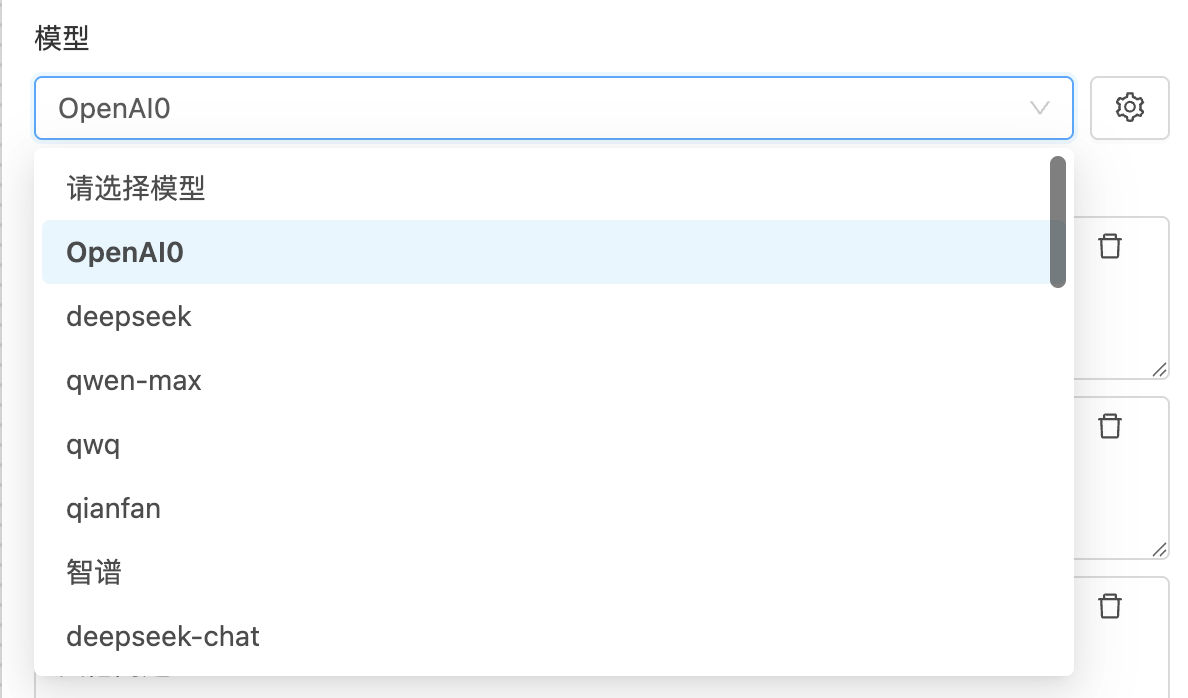
点击右侧图标可进入模型参数设置界面,可通过调整各项参数,以实现更加精准的控制目标:
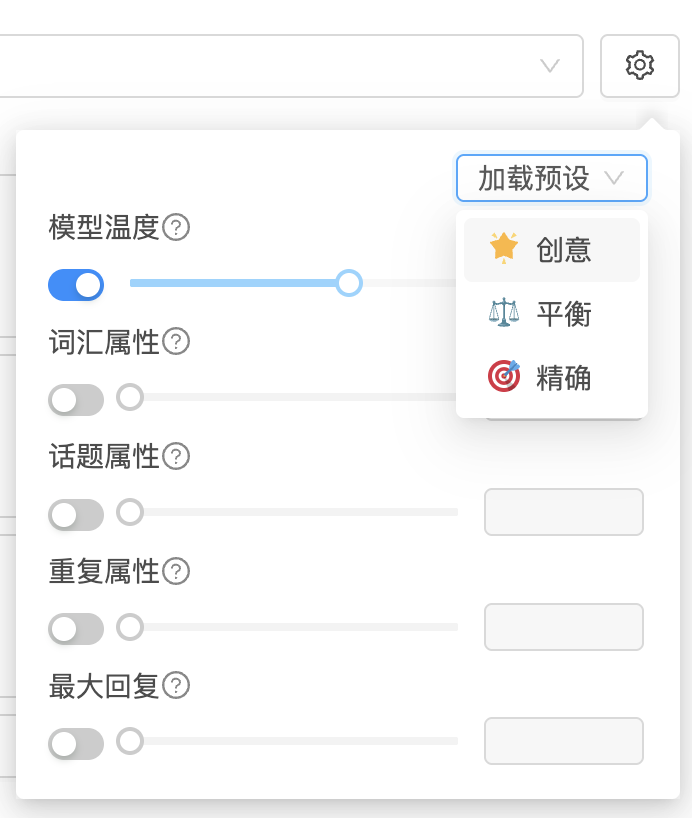
以下是各项模型参数的详细说明:
-
温度(Temperature): 控制生成内容的随机性。
- 数值越高,输出越有创意,但也越不可预测。
- 设置为
0时,模型将更加确定性地输出内容,适用于需要高准确率的任务。 - 推荐值:
0.5 ~ 0.8,适用于日常对话与内容生成。
-
词汇属性(Lexical Diversity): 控制语言表达的复杂程度与多样性。
- 数值较低生成内容更加简洁直白;
- 数值较高则适合用于创意写作与风格表达。
-
话题属性(Topicality): 决定模型是否容易引入新的话题。
- 增加该值可提升对话内容的拓展性;
- 一般建议保留默认值或根据需求微调。
-
重复属性(Repetition Penalty): 控制重复内容的比例。
- 值越高,模型越倾向于避免内容重复;
- 可在默认设置下使用,适配大多数场景。
-
最大回复长度(Max Tokens): 设置模型输出内容的最大字数限制。
- 普通问答建议设置为:
500 ~ 800 - 短文内容生成建议:
800 ~ 2000 - 编程代码输出建议:
2000 ~ 3600 - 长文创作建议设置为
4000或使用支持长文本生成的模型
- 普通问答建议设置为:
模型预设模式
- 精确模式: 内容更加符合指令,适用于对格式与语义要求较高的任务;
- 平衡模式: 在创造力与准确性之间取得平衡,适合大多数业务需求;
- 创意模式: 输出更具表现力与发散性,适合创意构思与内容创作。
3. 分类配置
使用自然语言对每个分类进行描述,LLM 模型会基于输入内容进行语义分析,从而判断应归属于哪一类。分类器节点会根据模型输出的分类结果,将流程流转至相应的分支。
默认情况下,分类器节点至少包含一个自定义分类与一个「ELSE」分类。若所有条件均不满足,则自动走向「ELSE」分支。
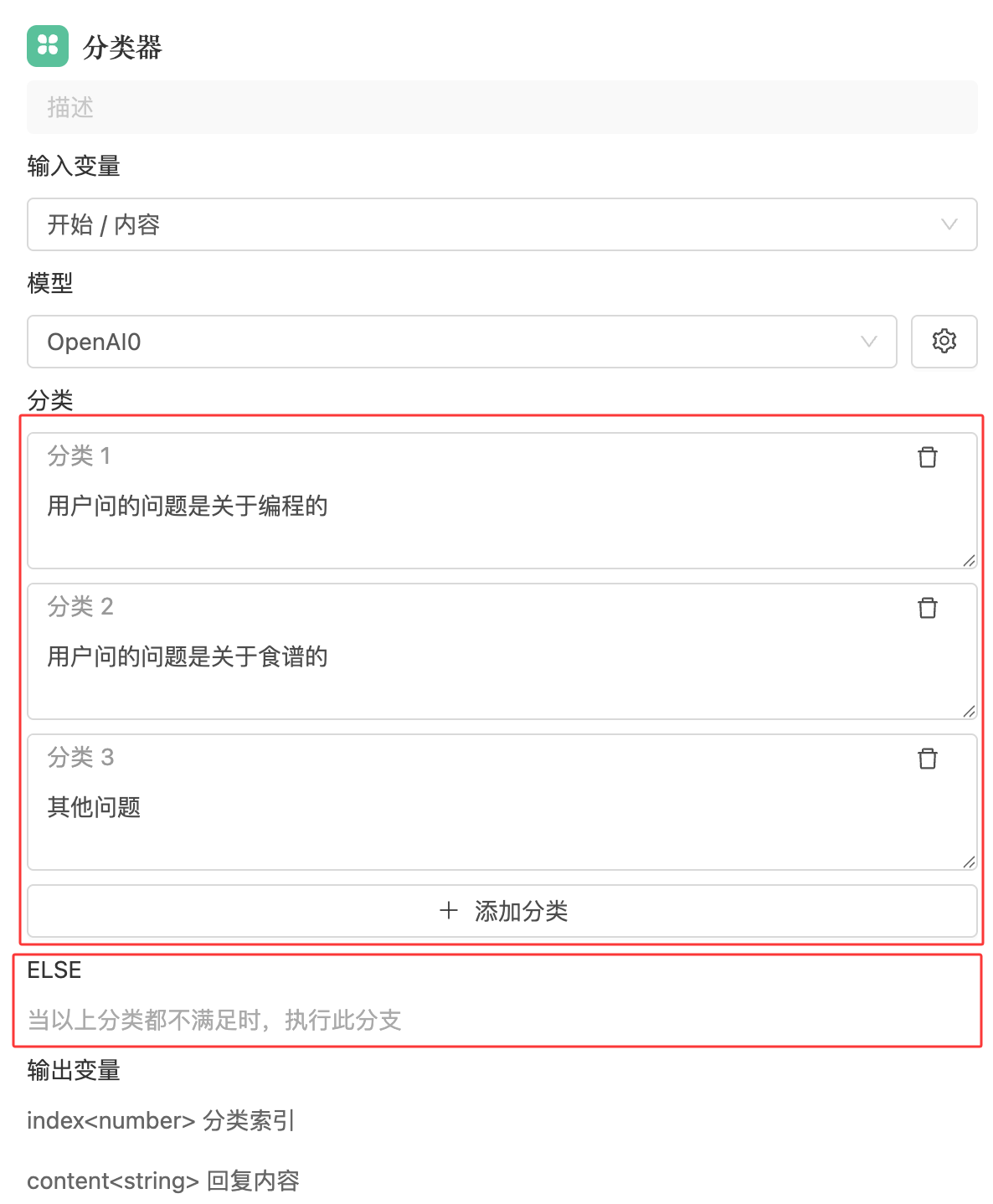
完成分类描述后,需要将每一个分类与工作流中的其他节点相连接,才能实现基于分类结果的自动分流。
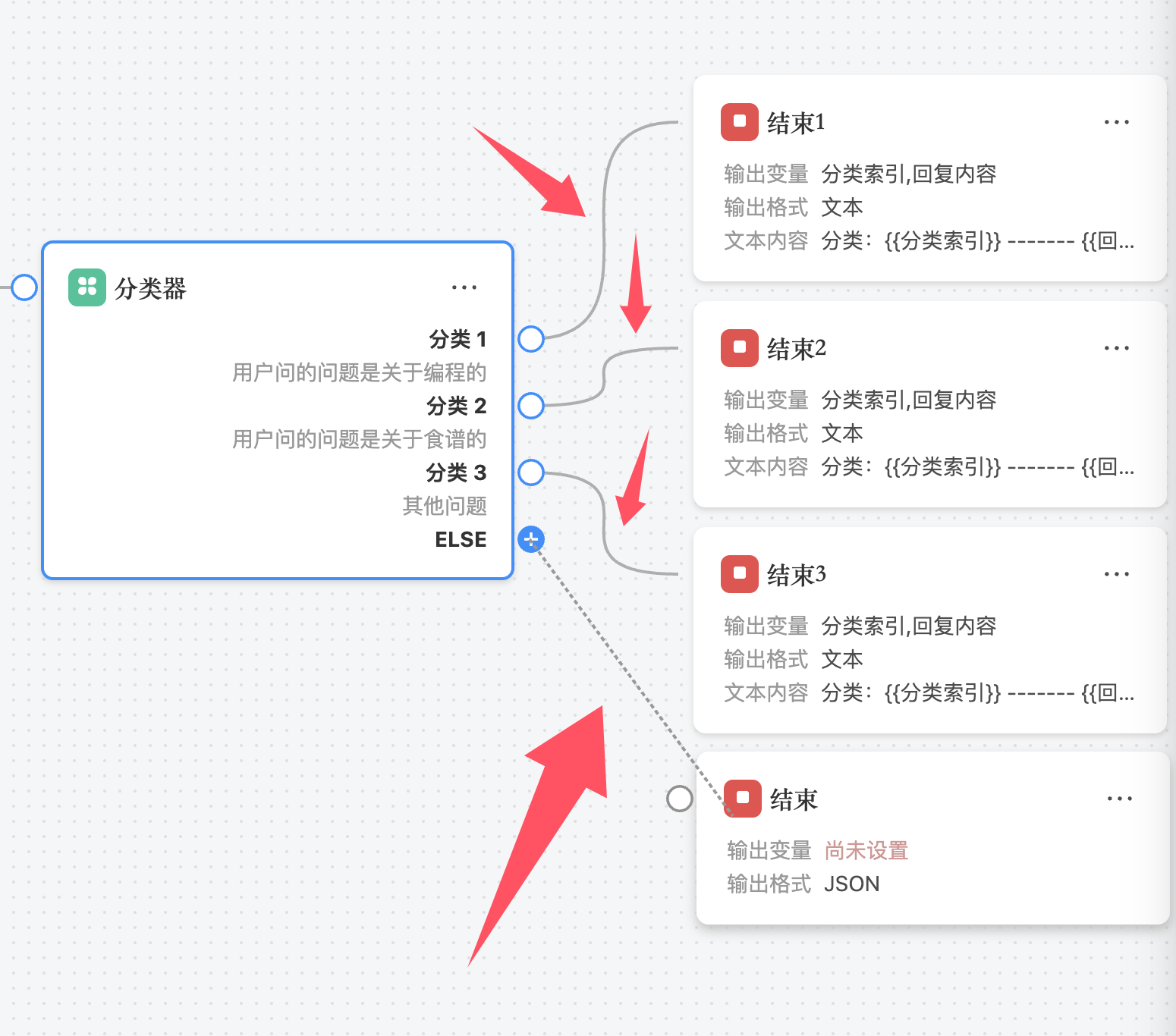
4. 输出变量
分类器节点将输出以下两个变量供后续节点使用:
- 分类索引(index): 表示所选分类的序号,索引从 0 开始,依次类推;
- 分类描述(content): 表示最终匹配的分类描述内容,也就是对应的意图或分类标签。