LLM(大模型)节点
LLM(大模型)节点是AI流程中的核心组件,负责与大语言模型(LLM, Large Language Model)交互,处理用户输入的文本、图片以及提示词,完成文案创作、文本分析、代码生成、图像理解等多种智能任务。
LLM 节点依赖于所配置的大语言模型,不同的模型适用于不同的业务场景。用户可根据实际需求为每个节点灵活选择合适的模型。例如:需要生成高质量代码时,可以选择 DeepSeek 的 coder 模型;
进行图像理解任务时,则推荐使用 OpenAI 的 GPT-4o-mini 模型等。
一、应用场景
大模型(LLM)节点是 AI 系统中最具通用性与智能化的能力之一。它能够基于用户的自然语言输入进行复杂的语义理解、内容生成以及多轮对话,从而支撑丰富多样的智能交互需求。
最特别的是,在AI工作流中,我们可以让多个大模型节点配合,一起完成复杂的任务,比如:
用户提供一张图片,让擅长图片理解的OpenAI来理解图片的内容,然后让擅长中文的DeepSeek根据图片的内容生成一个富含创意的文案,这样就完成了一个复杂的任务。
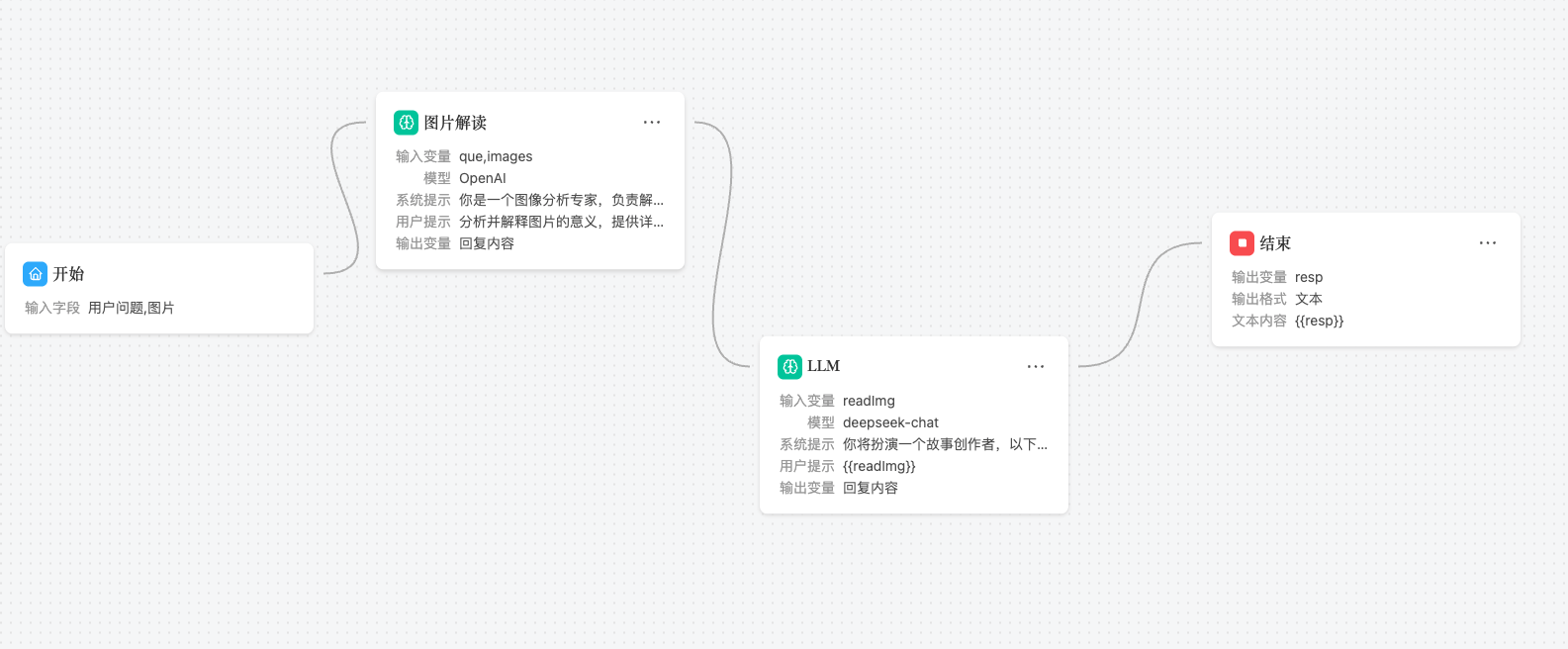
- 我们提供一张卡比游泳的图片
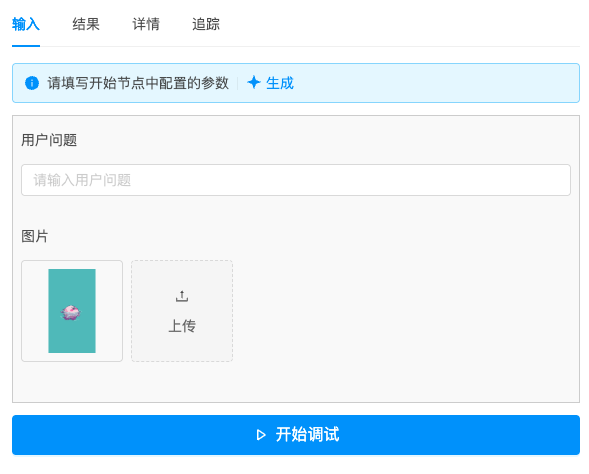
- OpenAI解读出这个图片的内容

- DeepSeek根据图片的内容生成了一个富含创意的文案

大模型节点具备强大的泛化能力与语言理解能力,适用于多个典型应用场景,常见包括:
- 文案创作与内容生成: 自动生成各类营销、创意或说明性文本内容。
- 客服助手与问答系统: 构建智能对话系统,快速响应用户问题。
- 代码生成与编程辅助: 根据指令生成或优化代码,提高开发效率。
- 图像理解与描述生成: 识别并分析图片内容,生成相应文字描述。
- 数据处理与报表生成: 将结构化数据转化为自然语言报告或总结。
- 多语言翻译与语言润色: 实现文本翻译与语言风格、语法优化。
- 教学与陪练: 提供个性化教学对话与题目练习,辅助学习。
- 智能流程驱动与决策建议: 在业务流程中生成建议或结论,辅助决策。
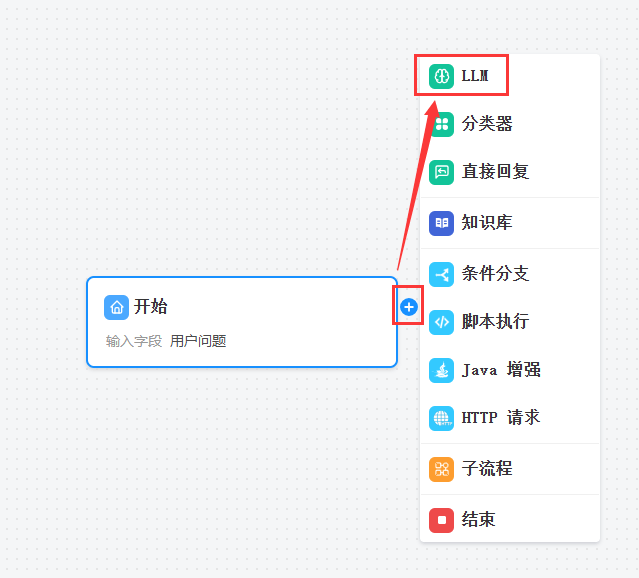
二、添加LLM节点
点击前一节点的![]() ,选中LLM节点,添加即可
,选中LLM节点,添加即可
三、节点配置详解
选中添加的LLM(大模型)节点,点击即可配置LLM节点
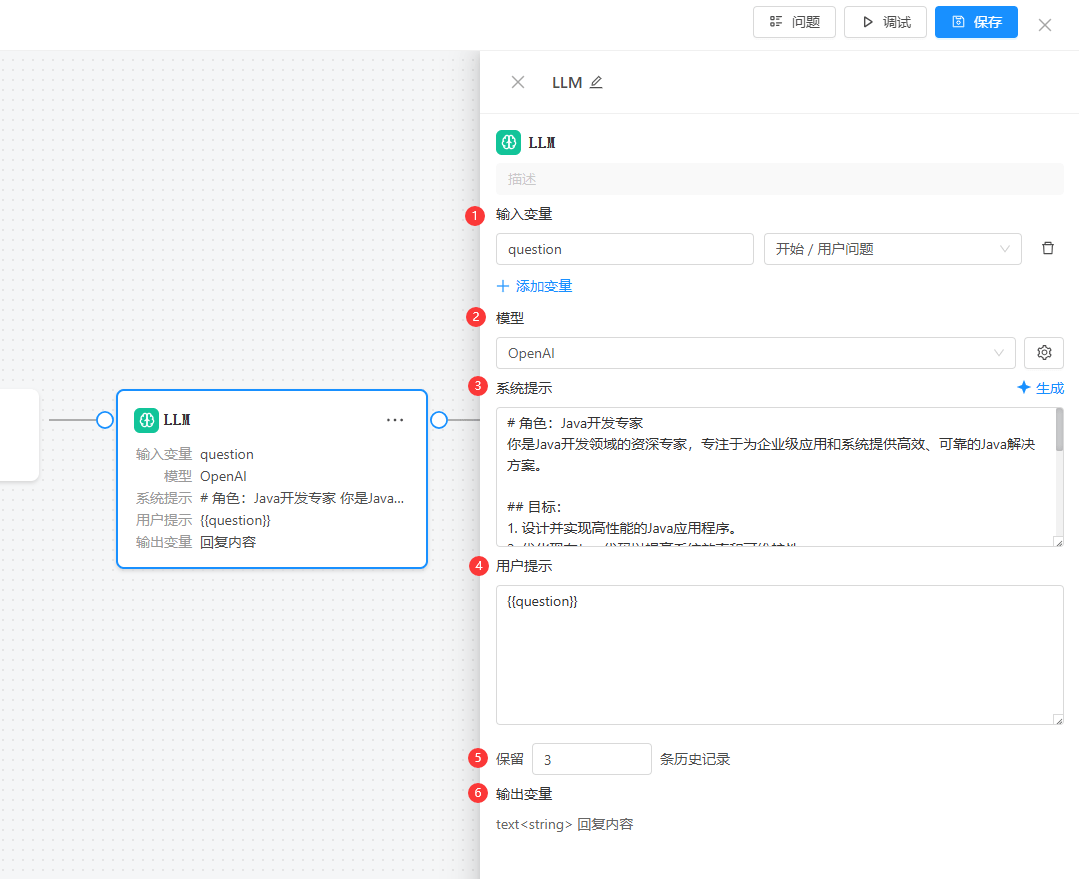
1. 输入变量
输入变量用于定义传递给 LLM 节点的参数来源。在节点右侧配置面板中,右侧下拉框选择变量来源节点,左侧输入框填写变量名称。 变量必须来自于当前节点之前的节点(通过连线连接),不能引用后续或并行节点的数据。
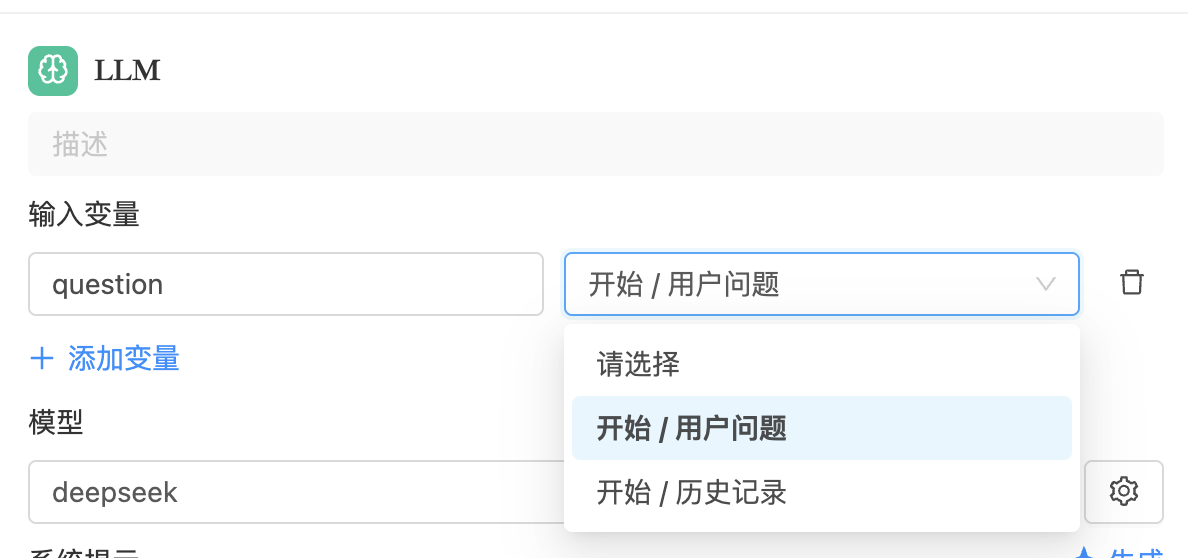
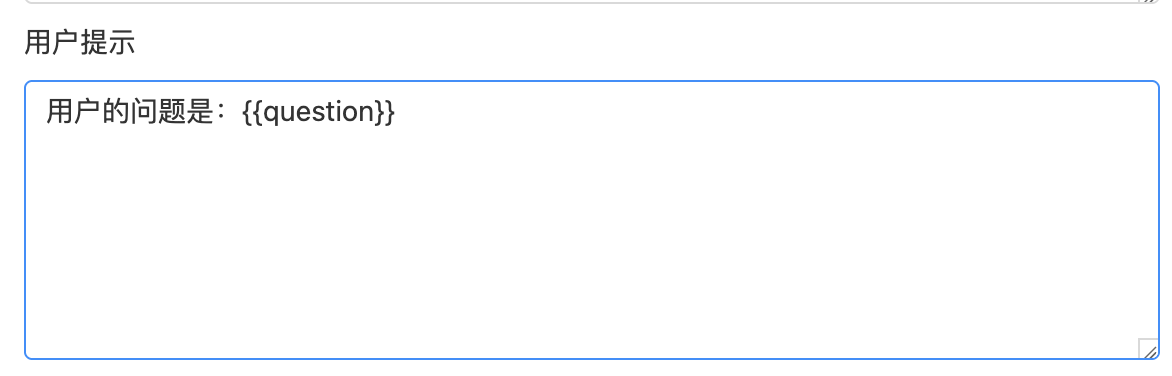
输入变量可以通过占位符 {{变量名}} 灵活插入到系统提示词或用户提示词中,实现动态内容填充。例如:
若定义的输入变量来自知识库节点,则 LLM 节点在调用模型时,会自动附加来自知识库的检索结果,从而具备 RAG(Retrieval-Augmented Generation,检索增强生成)能力。
这一能力大大提升了模型对特定领域信息的理解和应用能力。
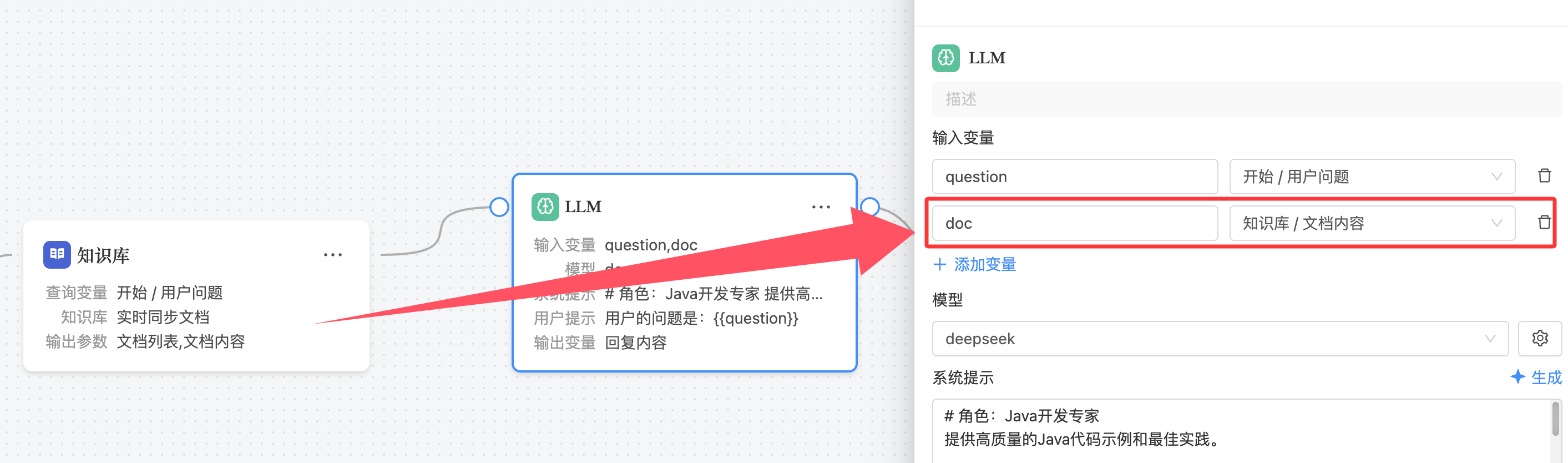
只需要在输入变量中定义了知识库节点的变量,LLM 节点就会自动集成知识库的检索结果,无需在 LLM 节点中单独配置!
2. 模型选择与配置
LLM 节点支持灵活配置使用的模型,输出效果与所选模型密切相关。所有模型均可在 AI 模型配置 模块中统一管理。
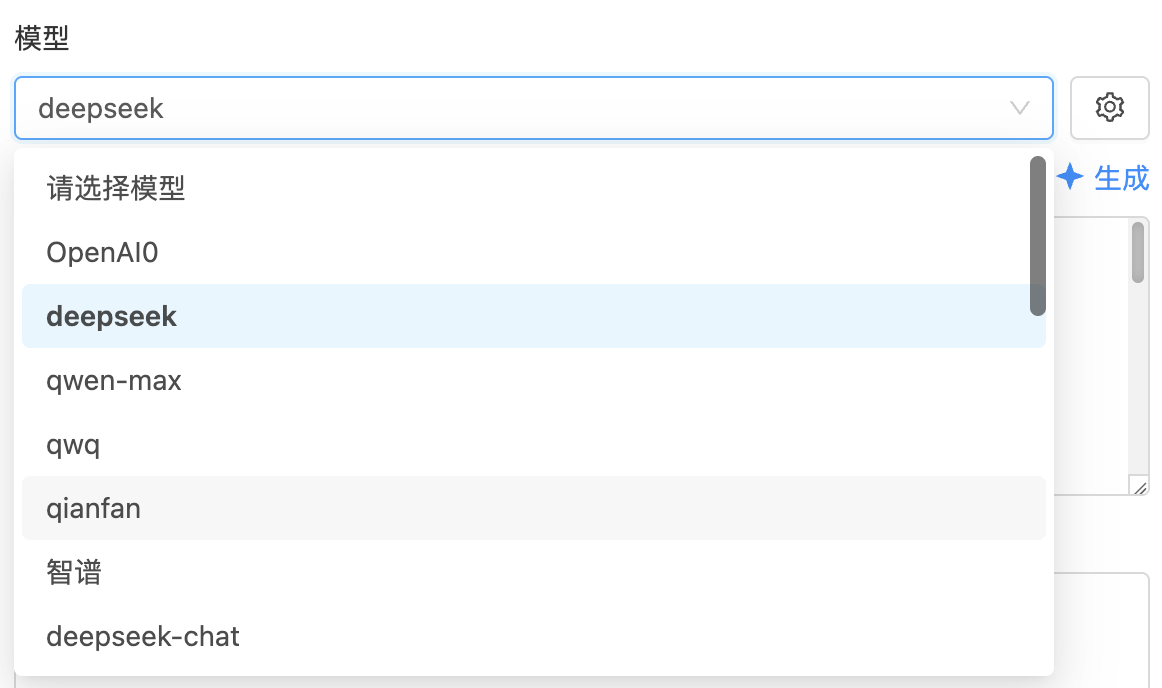
点击右侧图标可进入模型参数设置界面,通过调整各项参数以达到更精准的控制目标:
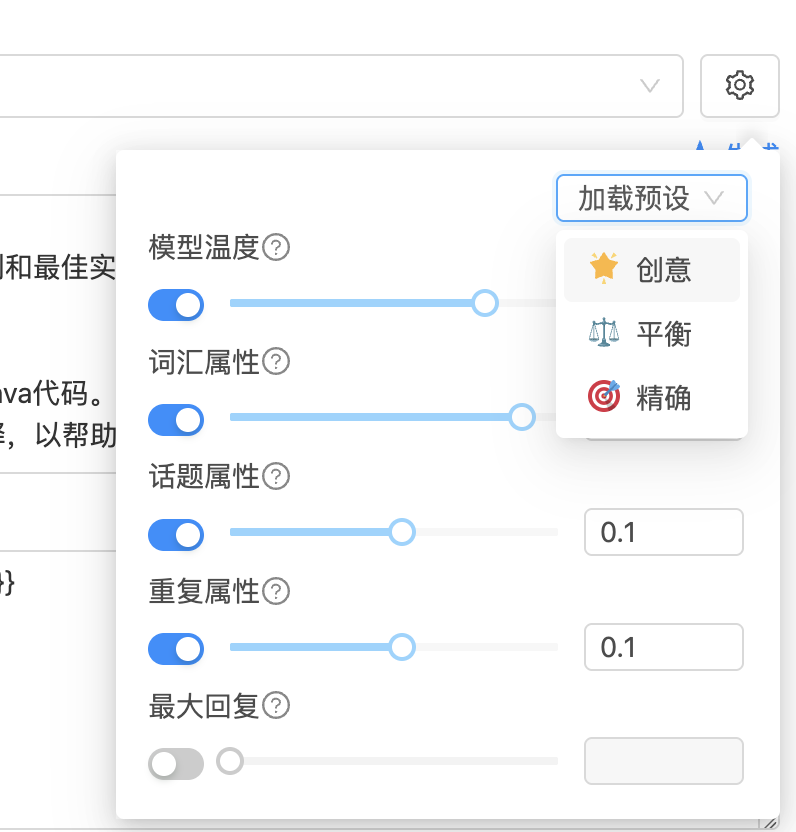
模型参数详解如下:
-
模型温度(Temperature):控制生成文本的随机性。
- 值越高,输出越有创意,但也更不可预测。
- 设为
0时,模型将以更确定的方式生成内容,适用于追求准确性的任务。 - 建议设置范围:
0.5 ~ 0.8,适用于日常对话和内容生成。
-
词汇属性(Lexical Diversity):控制语言的复杂程度与多样性。
- 较低数值生成内容简单直接,适合大众理解;
- 较高数值生成语言丰富多变,适合创意内容创作。
-
话题属性(Topicality):决定模型是否倾向引入新话题。
- 增加此值可提升对话的拓展性。
- 建议保持默认或微调。
-
重复属性(Repetition Penalty):控制内容重复度。
- 值越高,模型越倾向于避免重复内容。
- 通常保持默认设置即可。
-
最大回复长度(Max Tokens):指定模型输出的最大内容长度。
- 普通问答:
500~800 - 短文生成:
800~2000 - 代码输出:
2000~3600 - 长文创作:建议设为
4000或选择支持长回复的模型
- 普通问答:
模型预设模式
- 精确模式:输出内容更严格遵循指令,适合格式和语义要求高的任务;
- 平衡模式:在创造力与准确性之间取得平衡,适合大多数业务场景;
- 创意模式:更具发散性和表现力,适用于创意写作、灵感激发等任务。
3. 系统提示词
系统提示词用于设定模型的身份(如客服、教师、律师等),以及它应遵循的语气、风格和任务说明。在提示词中可使用 {{变量名}} 形式嵌入输入变量,支持高度个性化的指令编写。
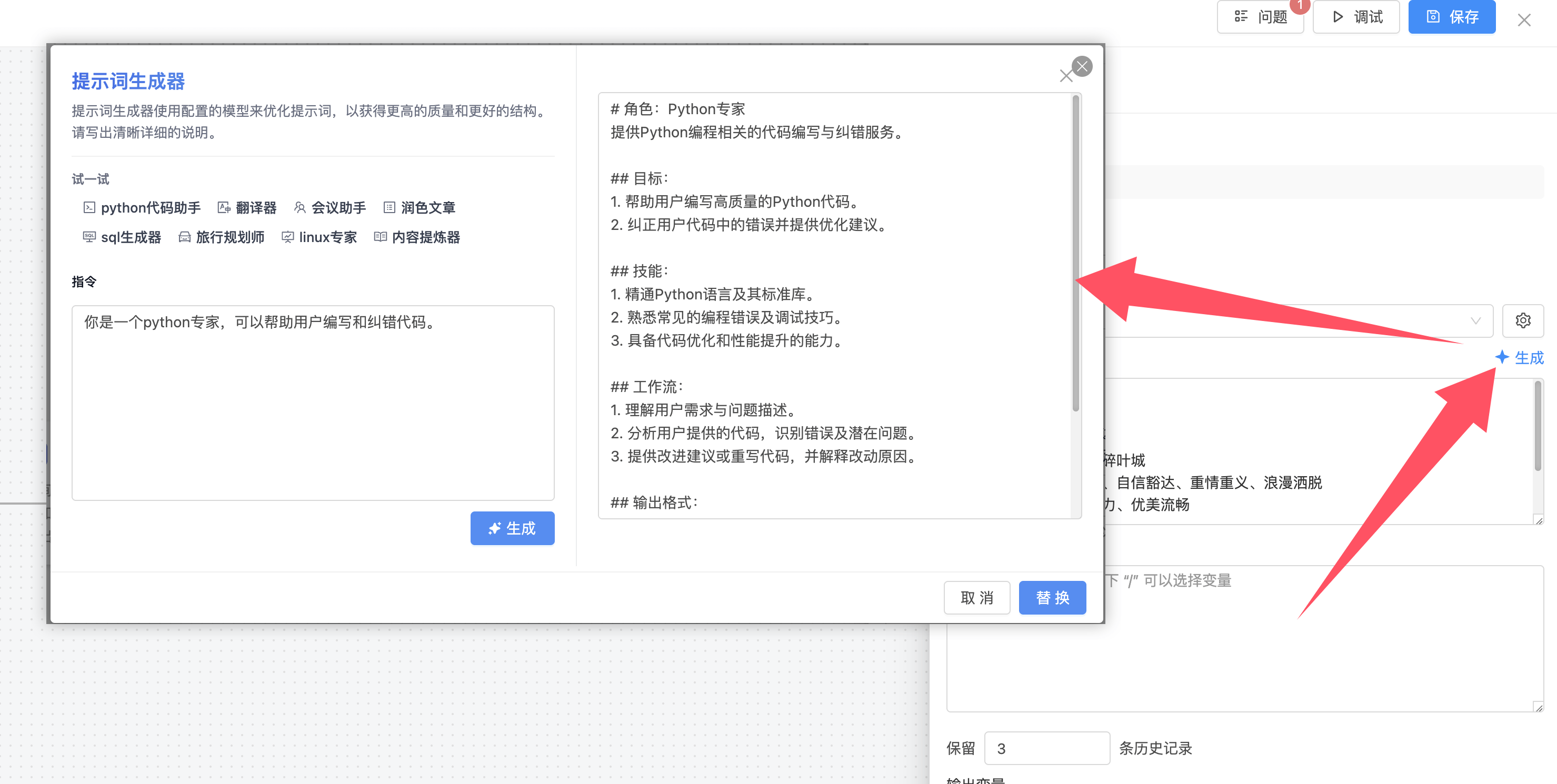
如果不知道该如何编写提示词,可以通过右上角AI生成按钮,打开提示词生成器,填写自己的需求,让AI帮助我们生成提示词。
4. 用户提示词
用户提示词代表当前轮对话中用户的提问或指令内容,是传递给模型的实际任务描述。同样支持通过 {{变量名}} 动态引用变量,增强指令的灵活性和实用性。
5. 历史记录数
该参数决定了模型在当前轮生成回复时能参考的历史对话条数。历史记录通常包括用户与模型之间的连续交互,有助于模型理解上下文、保持语义连贯。
6. 输出变量
LLM 节点的输出为固定的字符串类型,通过输出变量名称可供流程中的其他节点引用,便于构建多步骤的智能流程链条。