AI语音生成
1. 介绍
AI语音生成(TTS)功能可以将文本内容转换为自然流畅的语音音频。系统基于智谱AI的GLM-TTS模型,支持多种声色选择、语速调节和音量控制,适用于内容朗读、语音播报、视频配音等场景。
AI语音合成依赖智谱AI的TTS模型服务,使用前请确保已在"AI模型配置"中正确配置了相关API Key。
2. 功能概览
| 功能 | 说明 |
|---|---|
| 文本转语音 | 输入文案,一键生成语音音频 |
| 多声色选择 | 支持7种声色:彤彤、锤锤、小陈、Jam、Kazi、Douji、Luodo |
| 语速调节 | 支持0.25x ~ 4x 倍速调整 |
| 音量增益 | 支持-10dB ~ +10dB 音量调节 |
| 历史记录 | 自动保存生成历史,支持回放、复用和下载 |
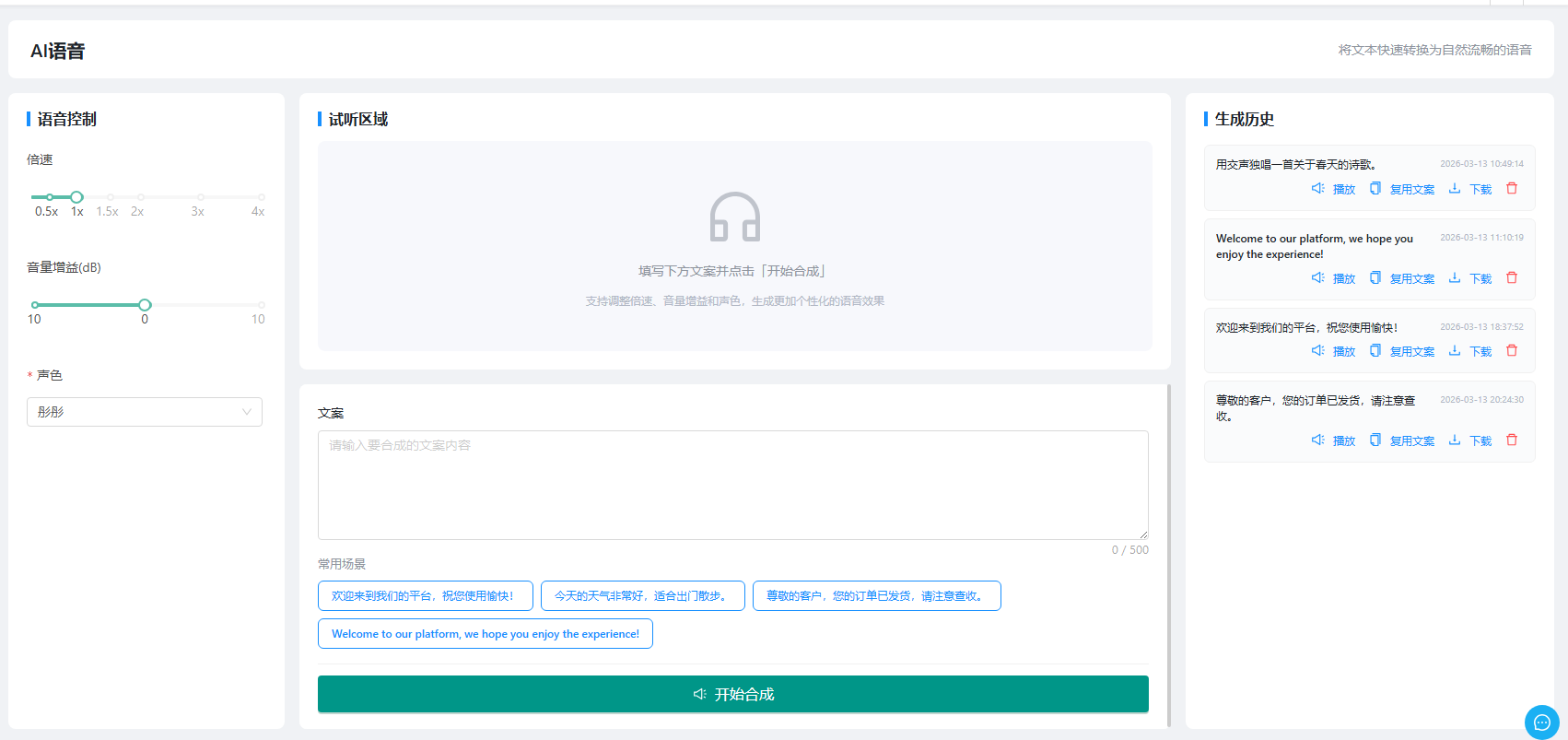
3. 操作界面
页面分为三个区域:
- 左侧 — 参数控制面板:设置倍速、音量增益、声色等参数
- 中间 — 试听与输入区域:输入文案内容,试听生成结果
- 右侧 — 生成历史列表:查看历史记录,支持播放、复用文案、下载、删除操作
4. 使用步骤
4.1 配置参数
在左侧面板中设置语音参数:

- 倍速:拖动滑块调整语速,默认1x,范围0.25x ~ 4x
- 音量增益(dB):拖动滑块调整音量,默认0dB,范围-10dB ~ +10dB
- 声色:从下拉框选择音色
彤彤— 女声,温柔自然(默认)锤锤— 男声,沉稳大气小陈— 男声,年轻活力Jam— 英文男声Kazi— 英文男声Douji— 中性声线Luodo— 中性声线
4.2 输入文案
在中间区域的文本框中输入要合成的内容(最多500字),也可点击下方的常用场景标签快速填入示例文案。
4.3 生成语音
点击"开始合成"按钮,系统将调用AI模型生成音频文件。生成完成后,可在中间区域直接试听。
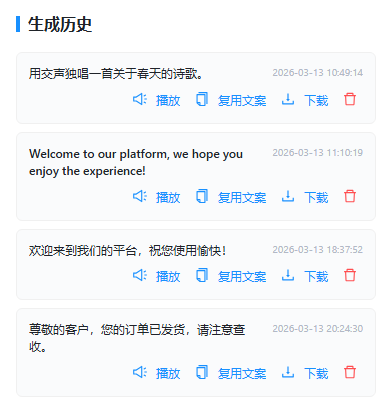
4.4 管理历史记录
右侧历史列表展示所有生成记录,支持以下操作:
- 播放:点击播放按钮试听
- 复用文案:将历史文案重新填入输入框
- 下载:下载音频文件到本地
- 删除:删除不需要的记录
5. 后台配置
在 application-dev.yml(或对应环境配置)中添加语音相关配置:
jeecg:
ai-chat:
ai-model-voice:
provider: ZHIPU
model: glm-tts
apiKey: 你的智谱AI API Key
apiHost: https://open.bigmodel.cn/api/paas/v4
timeout: 60
voice: alloy # 默认声色
speed: 1.0 # 默认倍速(0.25~4.0)
volume: 0.0 # 默认音量增益(dB)
6. API接口
| 接口 | 方法 | 说明 |
|---|---|---|
/airag/voice/generate | POST | 文本生成语音,传入文案、声色、倍速、音量等参数 |
/airag/voice/listByUser | GET | 查询当前用户的语音生成历史 |
/airag/voice/deleteVoiceRecord | DELETE | 删除指定的语音生成记录 |
7. 常见问题
Q:生成语音时提示失败?
A:请检查以下几点:
- 确认已正确配置智谱AI的 API Key
- 确认 API Key 余额充足
Q:语音文件保存在哪里?
A:生成的语音文件保存在服务器上传目录的 voice/ 文件夹下。