变量聚合节点
将多个上游变量按分组优先级合并成单个输出,遇到首个非空值即返回,常用于兜底回退与多路聚合。
一、应用场景
- 多模型/多通道返回内容择优合并,优先选用高置信度结果,失败自动降级到兜底文案。
- 不同数据源(API/数据库/缓存)按顺序取值,首个非空即作为最终输出,避免大量分支判断。
- 表单/消息内容多来源拼接,按分组聚合后统一变量名供下游调用。
- LLM 结果存在空值或格式异常时,自动回退到固定提示或默认值。
二、添加变量聚合节点
在画布中点击前一节点右侧的 ![]() ,选择变量聚合节点完成添加。
,选择变量聚合节点完成添加。
三、节点配置详解
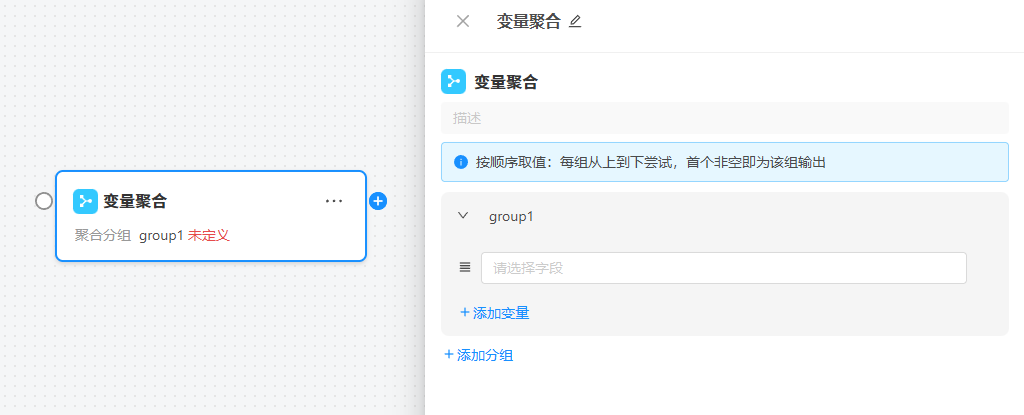
1. 分组管理
- 新增/删除分组: 最少保留 1 组,支持最多 20 组。删除需确认;新增后自动展开并可立即改名。
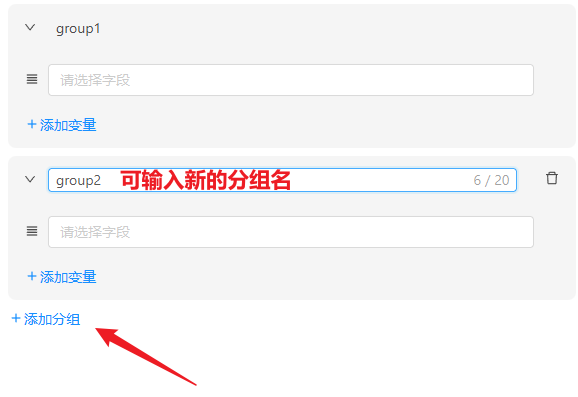
- 分组名即输出变量名: 可编辑,不能与其他分组重复,下游即可通过分组名引用聚合结果。
- 类型锁定: 分组类型由首个选择的上游变量决定,一旦确定不可更改;同组内其他变量必须同类型。
2. 变量列表
- 最少 1 个变量,支持拖拽排序。 拖拽不允许放到自定义值位置之下。
- 第 1 个变量必须选择上游节点的输出,禁止自定义。 变量来源仅能选择当前节点之前已连线节点的输出字段,不能引用并行或后续节点。
- 后续变量可继续选择上游输出,类型需匹配分组类型。 选择时会自动过滤不同类型的变量,避免类型冲突。
- 自定义兜底值: 仅允许出现在末尾位置,且需要分组类型为
string或number时才可输入;用于全部上游为空时的回退值。若在含兜底值的分组继续新增变量,系统会插入到兜底值之前。 - 删除变量: 组内至少保留 1 个变量,删除按钮对最后一个变量不可用。

3. 取值规则与后端行为
- 取值顺序: 按分组顺序依次处理;组内按从上到下取值,遇到首个“非空”值即视为该组输出并写入上下文,随后进入下一分组。
- 变量来源:
- 上游引用:根据所选
nodeId + field从上下文读取值。 - 自定义值:读取
customValue作为兜底。
- 上游引用:根据所选
- 空值判定(按类型):
string:非null且非空字符串。number:非null。boolean:非null。object:必须是 Map/Object 且非空。array(如string[]、number[]):必须是数组且非空。
- 未命中处理: 若整组均为空,则清除该分组在当前节点的上下文值。
4. 校验与提示
- 分组重复名、未选上游变量、未确定类型、变量缺失都会在保存/校验时提示。
- “成功”与“失败”分支不存在,该节点仅直连下一步;确保下游节点引用的分组名与当前配置一致。
四、示例
- 多通道结果聚合:
- 分组
finalText类型string,依次选择LLM 主通道.result、LLM 备份.result,最后自定义兜底 “抱歉,本次未生成结果”。 - 下游节点直接使用
{{finalText}}。
- 分组
- 数值回退: 分组
price类型number,依次取 API 返回价、数据库缓存价,最后兜底 0。
注意事项
- 分组名即输出字段,修改/删除分组会影响下游引用,请同步检查连线后的节点配置。
- 所有变量必须来自当前节点之前的已连接节点;并行或后续节点变量不可选。自定义值仅作兜底且需放在末尾。