记忆检索节点
从 AI 应用关联的记忆库中检索与查询内容相关的记忆片段,供下游节点使用。
该节点需要在 AI 应用中关联当前流程并配置记忆库才能正常工作。
一、应用场景
- 长期记忆召回:在多轮对话中,检索用户历史交互中沉淀的关键信息(如用户曾提到的偏好、需求、约束条件),使 AI 具备"记住用户"的能力。
- 个性化问答增强:结合 LLM 节点,将检索到的记忆片段注入提示词上下文,让 AI 回复更加贴合用户历史习惯和偏好。
- 知识沉淀复用:对于已通过"记忆写入"节点存入的经验、总结或决策结果,通过记忆检索节点在后续流程中复用,避免重复计算。
- 上下文补全:当单轮对话信息不足时,通过检索记忆库中的历史信息补充上下文,提升流程的理解和决策质量。
二、添加记忆检索节点
在画布中点击前一节点右侧的 ![]() ,在节点列表中选择记忆检索节点完成添加。
,在节点列表中选择记忆检索节点完成添加。
三、节点配置详解
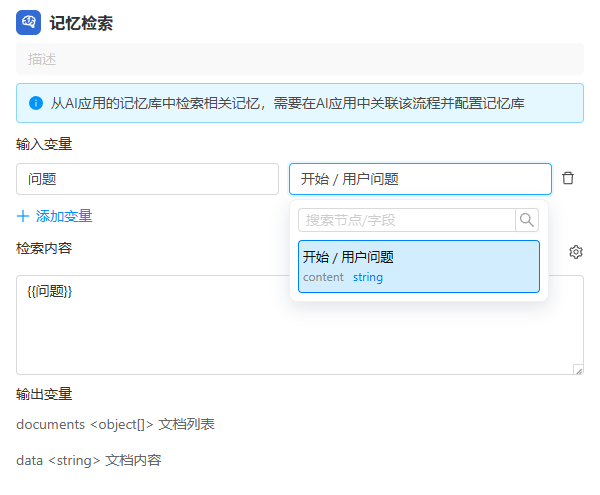
1. 输入变量
输入变量用于为检索内容中的 {{变量名}} 占位符提供实际值。
- 左侧输入框:填写变量名(与检索内容中
{{变量名}}对应)。 - 右侧下拉框:选择来源节点和字段,仅支持
string、number类型的变量。 - 变量来源必须是当前节点之前的串行节点,不能引用并行或后续节点的输出。
- 输入变量为可选配置,若检索内容中不包含变量占位符,可不配置。
2. 检索内容
检索内容是发送给记忆库进行向量检索的查询语句,节点会根据该内容在记忆库中匹配最相关的记忆片段。
- 支持直接输入关键词或完整语句。
- 支持通过
{{变量名}}引用输入变量,按下/可快捷选择变量。 - 检索内容不能为空,否则校验不通过。
参数配置
点击检索内容右上角的 ⚙ 设置图标,可配置以下检索参数:

| 参数 | 说明 | 默认值 |
|---|---|---|
| Top K | 返回相似度最高的前 K 条记忆片段,范围 1~10 | 5 |
| Score 阈值 | 开启后,低于该相似度分数的记忆将被过滤,范围 0~1 | 0.7 |
💡 合理调整 Top K 和 Score 阈值,可以在召回量和准确度之间取得平衡。Top K 越大召回越多但可能引入噪声;Score 阈值越高结果越精确但可能漏掉相关记忆。
3. 输出变量
记忆检索节点执行后输出以下两个变量,供下游节点引用:
| 字段名 | 类型 | 说明 |
|---|---|---|
| documents | object[] | 检索到的文档片段数组,包含完整的结构化信息 |
| data | string | 所有检索到的文档正文合并后的纯文本,便于直接注入 LLM 提示词 |
下游节点可通过变量选择器引用,例如在 LLM 节点的提示词中使用 {{data}} 获取检索结果文本。
4. 配置示例
假设需要根据用户当前提问,从记忆库中检索相关的历史交互记忆:
- 添加输入变量:变量名
question,来源选择开始节点的query(用户输入)。 - 检索内容填写:
{{question}}。 - Top K 设为
3,开启 Score 阈值并设为0.75。
执行后,data 输出检索到的记忆文本,documents 输出结构化文档列表。在下游 LLM 节点中,可将 {{data}} 插入系统提示词,使模型结合记忆进行回答。
四、注意事项
该节点必须在 AI 应用中关联流程并配置记忆库后使用。若未配置记忆库,节点执行时将报错:"记忆检索需要关联AI应用并配置记忆库"。
记忆库与知识库使用相同的向量检索技术,但记忆库面向的是动态写入的用户交互记忆,而知识库面向的是预先导入的静态文档。
检索内容支持
{{变量名}}占位符,运行时会自动替换为输入变量的实际值。若占位符对应的变量未配置或值为空,则替换为空字符串。