知识库写入节点
知识库写入节点用于将流程中产生的文本内容写入到指定知识库,从而实现知识库数据的动态更新与扩充。该节点是构建自动化知识积累、数据采集入库等场景的核心组件。
一、应用场景
- 自动采集入库:将 HTTP 节点抓取的外部数据经 LLM 整理后,自动写入知识库,构建持续更新的知识体系。
- 对话摘要沉淀:在客服/咨询场景中,将对话结束后的对话摘要写入知识库,供后续查询复用。
- 文档自动归档:将用户上传的文本、表单正文等结构化内容自动写入知识库,实现文档集中管理。
- 数据清洗入库:结合代码节点或 LLM 节点对原始数据进行清洗、格式化后,再写入知识库。
- 知识库动态扩充:基于用户反馈或业务变化,通过流程自动向知识库追加新内容,保持知识库的时效性。
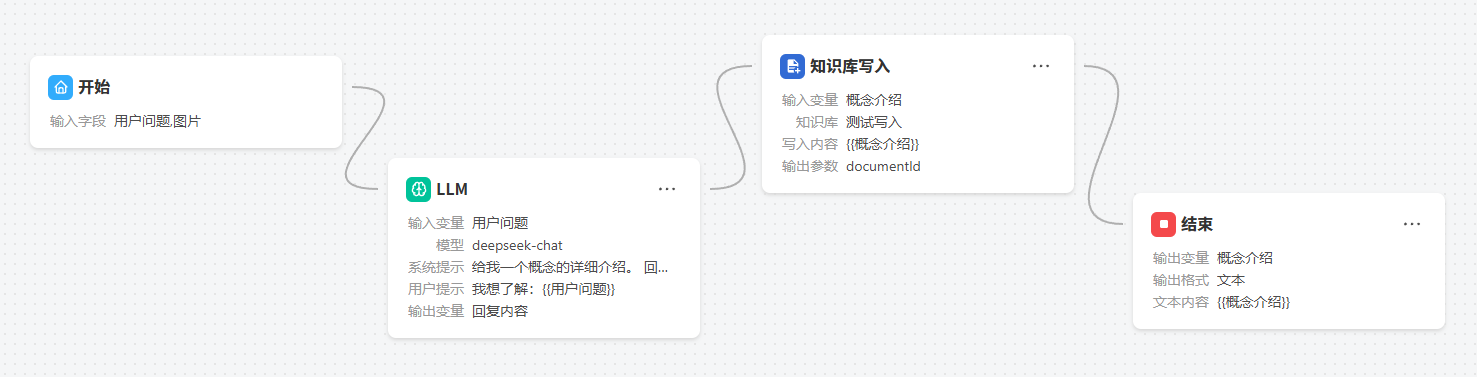
二、添加知识库写入节点
在画布中点击前一节点右侧的 ![]() ,选择知识库写入节点完成添加。
,选择知识库写入节点完成添加。
三、节点配置详解
选中添加的知识库写入节点,即可打开配置面板进行详细配置。
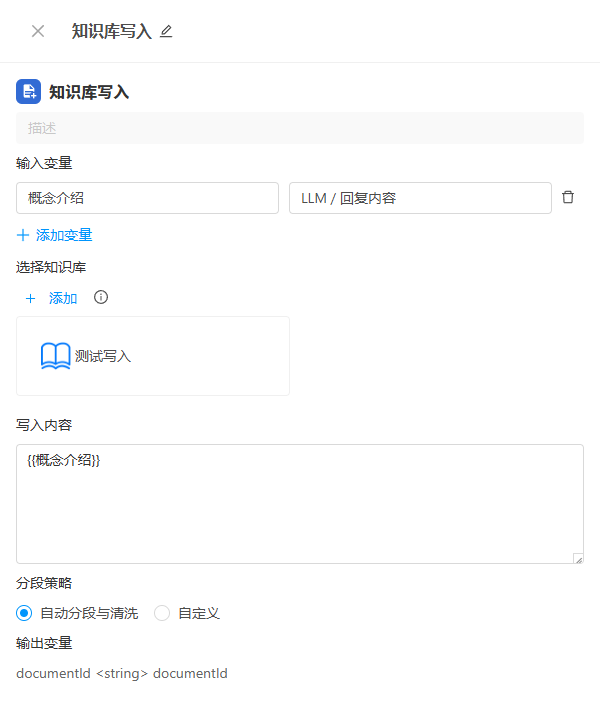
1. 输入变量
输入变量用于将前置节点的输出数据传递到当前节点,作为写入内容中的动态占位符来源。
- 左侧输入框:填写变量名称(如
content、summary),用于在写入内容中通过{{变量名}}引用。 - 右侧下拉框:选择变量来源,仅可选择当前节点之前的节点输出变量。
- 类型限制:仅支持
string和number类型的变量。
变量必须来自当前节点之前的节点(通过连线连接),不可引用并行或后续节点的变量。
2. 选择知识库
点击添加按钮,在弹出的知识库选择面板中选择目标知识库。
仅支持选择 1 个知识库,如果选择了多个知识库,系统会自动保留第一个。
选中的知识库会以卡片形式展示在配置面板中,鼠标悬停可显示删除按钮,点击即可移除。
3. 写入类型
支持两种写入方式,可在「写入类型」单选框中切换:
| 写入类型 | 说明 | 适用场景 |
|---|---|---|
| 文本写入 (默认) | 直接将文本内容写入知识库 | 对话摘要、LLM 输出、HTTP 抓取后清洗的纯文本 |
| 文件写入 | 引用开始节点 file 字段输出的文件 URL,由系统下载并解析文件后写入知识库 | 用户上传 PDF/Word/Excel 等附件,希望直接把原文档落库 |
4. 写入内容 / 文件来源
4.1 文本写入
在文本编辑区域中填写需要写入知识库的内容。支持纯文本输入,也支持通过 {{变量名}} 引用输入变量,实现动态内容拼接。
- 输入
/可快速插入前置节点的变量。 - 占位符格式为
{{变量名}},运行时自动替换为输入变量的实际值。 - 写入内容不能为空,否则节点校验不通过。
示例:
以下是用户咨询的问题摘要:
问题:{{question}}
回答:{{answer}}
记录时间:{{timestamp}}
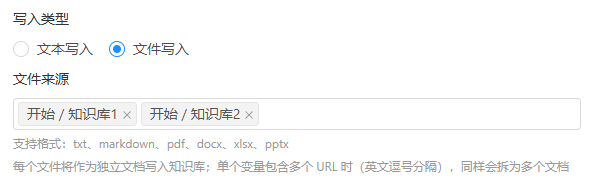
4.2 文件写入
切换到「文件写入」后,会显示文件来源下拉选择框,可多选前置节点中所有 file 类型的输出变量(最典型的是开始节点配置的 file 类型字段,对应文件上传组件)。
- 选项来源:所有前置节点的
file类型变量,显示为节点名 / 字段名 - 支持多选:可以同时引用多个前置节点的多个文件变量,节点会依次写入
- 每个文件作为独立文档写入知识库;单个变量包含多个 URL 时(英文逗号分隔),同样会拆分为多个文档分别落库
- 支持的文件格式 :
txt、markdown(md)、pdf、docx/doc、xlsx/xls、pptx/ppt - 任一文件扩展名不在支持列表内会立即抛出业务异常,整个节点停止执行
- 若前置节点中没有 file 类型变量,下拉框会显示提示:「前置节点中暂无文件类型变量,请先在开始节点中添加 file 类型字段」
开始节点
file字段在运行时的值是「文件 URL 字符串,多个用英文逗号分隔」。节点会自动展开成单个 URL 后逐个写入知识库,无需用户手动拼接。
这里的下拉选择与上方「输入变量」区域无关 —— 输入变量仍然仅支持
string/number用于文本占位符;file 类型变量通过本下拉直接绑定到节点上下文,节点运行时按节点 ID + 字段名取值。
5. 分段策略
分段策略决定了写入内容如何切分成多个文档片段进行向量化存储。提供两种模式:
① 自动分段与清洗(默认)
系统自动根据文本内容智能切分与清洗,无需手动配置,适合大多数场景。
② 自定义分段
选择"自定义"后,可精细控制分段行为:

| 配置项 | 说明 |
|---|---|
| 分段标识符 | 用于拆分文本的分隔符,支持:换行、2个换行、中文句号/叹号/问号、英文句号/叹号/问号、自定义 |
| 自定义分段标识符 | 当分段标识符选择"自定义"时填写,可输入任意字符串作为分隔符 |
| 分段最大长度 | 每个文档片段的最大字符数,范围 100~5000,默认 800 |
| 分段重叠度% | 相邻片段之间的重叠比例,范围 0~90,默认 10。适度重叠可保证语义连贯性 |
| 文本预处理规则 | 可选,支持以下预处理操作: |
文本预处理规则选项:
- 替换掉连续的空格、换行符和制表符:清理文本中多余的空白字符
- 删除所有 URL 和电子邮箱地址:去除文本中的链接和邮箱信息
6. 等待向量化完成
知识库文档写入后是异步向量化的,默认情况下节点写入完毕立即返回,向量化在后台继续执行。如果后续流程需要立刻命中刚写入的内容,可开启「等待向量化完成」开关,节点会阻塞到所有文档处理完毕再进入下一步。
| 配置项 | 说明 |
|---|---|
| 等待向量化完成 | 开关,默认 关闭(兼容旧节点) |
| 超时时间(秒) | 仅开启时显示,范围 30 ~ 1800,默认 300(5 分钟) |
| 向量化失败/超时后 | 仅开启时显示: 报错并中断流程:发现失败立即抛错;超时也抛错(快速失败语义) 忽略并继续流程(默认):等所有文档处理完成(含失败);超时则直接放行 |
开启等待会阻塞整条流程,长文档或大批量场景下请合理设置超时;推荐先用默认 5 分钟,根据实际情况调整。
即使配置「忽略并继续」+ 超时,已写入的文档不会回滚——向量化仍在后台继续进行,最终状态由
airag_knowledge_doc.status字段记录。
7. 输出变量
知识库写入节点执行成功后,输出以下变量:
| 变量名 | 类型 | 说明 |
|---|---|---|
| documentId | string | 单文档场景下为新增文档 ID;多文档场景下为所有 ID 的英文逗号拼接字符串 |
| documentIds | string[] | 新增文档 ID 数组,按写入顺序提供;单文档场景下为只含 1 个元素的数组 |
- 下游普通节点(LLM、Reply、Code 等)通常引用
documentId即可 - 循环节点遍历多文档场景时,推荐引用
documentIds,可直接作为array类型循环源
四、配置示例
示例 1:对话摘要写入知识库(文本写入)
- 输入变量:配置变量
summary,来源为上游 LLM 节点的输出result。 - 选择知识库:选择"客服对话摘要库"。
- 写入类型:选择「文本写入」。
- 写入内容:
{{summary}}
- 分段策略:选择"自动分段与清洗"。
- 预期输出:节点执行后,
documentId将返回新写入文档的唯一标识。
示例 2:用户上传文件直接入库(文件写入)
- 开始节点:新增一个
file类型字段doc_path,限制支持的扩展名为pdf,docx。 - 知识库写入节点:
- 选择知识库:选择"产品资料库"。
- 写入类型:选择「文件写入」。
- 文件来源:下拉框中勾选
开始 / doc_path(可同时勾选其他前置 file 变量)。
- 分段策略:根据文件长度选择"自定义"并调节最大分段长度。
- 预期输出:用户每上传 1 个文件,知识库中新增 1 条
type=file文档并自动触发向量化,documentId返回新增文档 ID(多文件以逗号拼接)。
五、注意事项
使用知识库写入节点前,请确保已在系统中创建好目标知识库,否则将无法选择知识库。
文件写入模式下,文件来源只能从下拉选择前置节点的
file类型变量,不再通过{{}}占位符引用;文件扩展名必须在支持列表内。
写入的文档标题由系统自动生成(格式为"节点名称-时间戳"),文件写入模式下多文件会自动追加
-序号后缀。
- 每次节点执行会向知识库新增一个或多个文档,适合增量写入场景。
- 文本写入模式下,
{{变量名}}占位符对应变量值为空时替换为空字符串。 - 文件写入支持的格式与知识库文档功能完全一致:
txt / markdown(md) / pdf / docx, doc / xlsx, xls / pptx, ppt。 - 自定义分段策略中的参数配置,直接影响后续知识库检索的精度和召回率,建议根据实际内容特点进行调优。