当前用户信息节点
当前用户信息节点用于在流程执行时读取当前登录用户的基本信息,并将所选字段作为变量输出给下游节点使用。
一、应用场景
- 个性化问候与提示词:在 LLM 节点的提示词中引用
{{realname}},自动填充用户真实姓名,生成"你好,张三!"式的个性化回复。 - 基于部门/角色的业务分支:通过 Switch 节点判断
{{orgCode}}或{{roleCode}},为不同部门或角色分配不同的处理流程。 - 业务单据自动填入:将用户的工号、姓名、邮箱等信息直接注入到生成的工单、报表或审批模板中,减少手动填写。
- 审批与权限管控:将用户 ID、部门 ID 传递给 HTTP 节点或 Java 节点,调用下游业务接口时携带身份信息以满足权限校验。
- 日志与审计追踪:将用户账号或 ID 写入流程输出,便于后续对 AI 流程的执行记录进行归因分析。
二、添加当前用户信息节点
在画布中点击前一节点右侧的 ![]() ,在节点列表中选择当前用户信息节点完成添加。
,在节点列表中选择当前用户信息节点完成添加。
三、节点配置详解
点击画布中已添加的当前用户信息节点,右侧会展开配置面板。
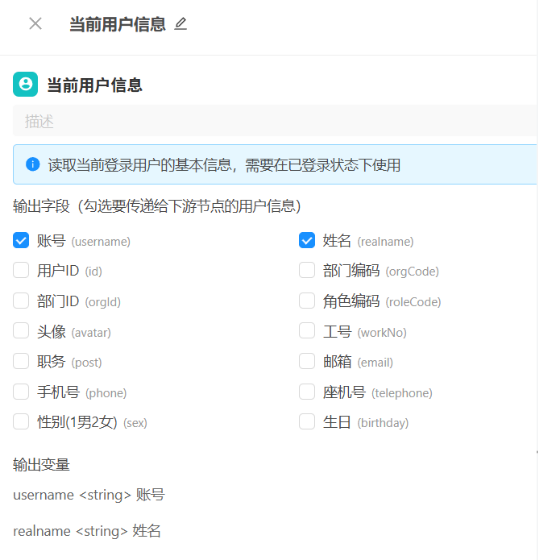
1. 输出字段配置
配置面板上方显示蓝色提示:读取当前登录用户的基本信息,需要在已登录状态下使用。
勾选复选框即可选择要向下游节点暴露的用户字段,可多选。默认勾选账号(username)和姓名(realname),其余字段按需勾选。
至少需要勾选一个字段,否则节点校验不通过、无法保存。
全部可选字段说明如下:
| 字段名(变量 key) | 显示名称 | 类型 | 默认勾选 |
|---|---|---|---|
username | 账号 | string | ✅ |
realname | 姓名 | string | ✅ |
id | 用户ID | string | — |
orgCode | 部门编码 | string | — |
orgId | 部门ID | string | — |
roleCode | 角色编码 | string | — |
avatar | 头像 | string | — |
workNo | 工号 | string | — |
post | 职务 | string | — |
email | 邮箱 | string | — |
phone | 手机号 | string | — |
telephone | 座机号 | string | — |
sex | 性别(1男2女) | number | — |
birthday | 生日 | string | — |
birthday字段输出格式为yyyy-MM-dd,例如1990-06-15。sex字段输出数字:1表示男,2表示女。
2. 输出变量
勾选字段后,配置面板下方的输出变量列表会自动更新,展示当前节点将会输出的所有变量名及类型。
下游节点可通过 {{字段名}} 占位符或变量选择器引用这些输出,例如:
- 在 LLM 提示词中写入
你好,{{realname}},你的账号是 {{username}},流程执行时会自动替换为真实值。 - 在 Switch 节点的条件中选择
当前用户信息.roleCode进行分支判断。
3. 配置示例
场景:在 LLM 节点中生成个性化问候语。
- 添加当前用户信息节点,勾选
username(账号)和realname(姓名)。 - 连接 LLM 节点,在 LLM 节点的输入变量中引用本节点的
realname字段。 - 在 LLM 系统提示词中写入:
你正在为用户
{{realname}}提供服务,请以友好、专业的语气回复。
预期输出:LLM 节点收到含有真实用户姓名的提示词,生成个性化回复。
四、注意事项
本节点必须在已登录状态下执行。若流程在未登录环境中运行(例如通过匿名接口调用),节点将无法获取当前用户信息并抛出异常。
本节点没有输入变量,无需配置来源节点。节点直接从当前请求的登录上下文(JWT Token 或会话缓存)中读取用户信息。
字段勾选顺序决定输出变量的顺序,建议仅勾选下游实际需要的字段,避免暴露不必要的用户信息。